With the rise of artificial intelligence, automation is becoming a part of everyday life. Natural Language Processing (NLP) has proven to be a key part of this breakthrough. Natural Language Processing bridges the gap between computers, AI, and computational linguistics. Learn more about NLP approaches this guide to statistical and symbolic NLP.
A simple sentence spoken by humans consists of different tones, words, meanings, and values. Expert AI systems are able to leverage these hidden structures and meanings to understand human behaviour. However, we often need a very close and detailed assessment to conclude what meaning might and might not be correct. When we have a large amount of text data, it can become impossible to read quickly.
Raw text data in English or other languages is an example of unstructured data. This kind of data does not fit into a relational database and is hard to interpret with computer programs. Natural language processing is a sub-field of AI which deals with how computers interpret, comprehend, and manipulate human language.

How would you train an NLP algorithm to handle long Danish compound words like “Håndværkergården” (“the artisan farm”)? Would you make a dictionary of every possible compound, or try to split words up into their constituent parts?
NLP is much more than speech and text analysis. Depending on what needs to be done, there can be different approaches. There are three primary approaches:
Statistical Approach: The statistical approach to natural language processing depends on finding patterns in large volumes of text. By recognising these trends, the system can develop its own understanding of human language. Some of the more cutting edge examples of statistical NLP include deep learning and neural networks.
Symbolic Approach: The symbolic approach towards NLP is more about human-developed rules. A programmer writes a set of grammar rules to define how the system should behave.
Connectionist Approach or “Hybrid” Approach: The third approach is a combination of statistical and symbolic approaches. We start with a symbolic approach and strengthen it with statistical rules.
Now, let’s see how these NLP approaches are used by machines to interpret language.
Language interpretation can be divided into multiple levels. Each level allows the machine to extract information at a higher level of complexity.
Morphological Level: Within a word, a structure called the morpheme is the smallest unit of meaning. The word ‘unlockable’ is made of three morphemes: un+lock+able. Similarly, ‘happily’ is made of two: happy+ly. Morphological analysis involves identifying the morphemes within a word in order to get at the meaning.
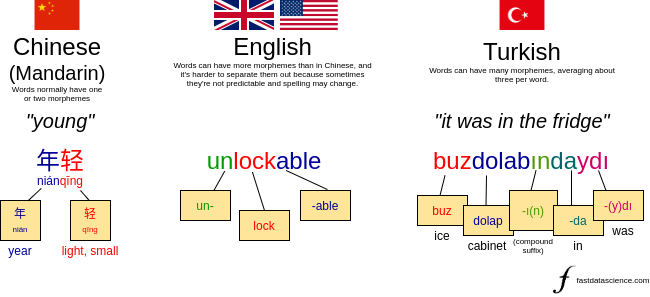
A Chinese word, an English word, and a Turkish word. Some languages, such as Mandarin, have one or two morphemes per word, and others, such as Turkish, can have many morphemes per word. English is somewhere in the middle. The example shown of ‘unlockable’ can be analysed as either un+lockable or unlock+able, which illustrates the inherent ambiguity of many of the analyses we run in NLP.
In practice, in English NLP, apart from removing suffixes like “ing” from words, we wouldn’t usually need to go into the morphological level. For highly inflected languages such as Shona, dealing with sub-word morphemes may be unavoidable. I have gone into more detail in my post on multilingual NLP.
Lexical Level: The next level of analysis involves looking at words at a whole.
An example of an entirely lexical NLP approach is a Naive Bayes classifier, which can categorise texts as sport or politics, spam or ham, based on word frequency and ignoring sentence structure.
Syntactic Level: Taking a step forward, syntactic analysis focuses on the structure of a sentence: how words interact with each other.
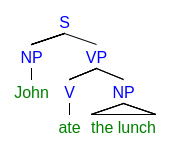
A parse tree is one way we can represent the syntax of a sentence.
An NLP system operating on the syntactic level might pick up the difference between “this movie was worth watching” and “the movie is certainly not worth watching”. These nuances are hard to pick up with a bag-of-words technique like the Naive Bayes Classifier.
Semantic Level: Semantic analysis deals with how we can convert the sentence structure into an interpretation of meaning.
A semantic NLP approach might be able to produce insights like “40% of doctors thought there was an interaction between drug A and drug B.”
Discourse Level: Here we are dealing with the connection between two sentences. This is incredibly tricky: if somebody says ‘he’, how do we know who they are referring to from a past sentence, if multiple persons were mentioned?
(In 2008, I wrote my Masters thesis on the word “it”, focusing on how we can distinguish pleonastic “it” as in “it’s raining” from the “it” that refers to something in a previous sentence. In the age of GPT, the problem remains unsolved!)
Now that we have a clear understanding of natural language processing, here are some common examples of NLP:

Out-of-control social media can be damaging for a brand.
One of the best examples of natural language processing is social media monitoring. Negative publicity is not good for a brand and a good way to know what your customers think is by keeping an eye on social media.
Platforms like Buffer and Hootsuite use NLP technology to track comments and posts about a brand. NLP helps alert companies when a negative tweet or mention goes live so that they can address a customer service problem before it becomes a disaster.

While standard social media monitoring deals with written texts, with sentiment analysis techniques we can take a deeper look at the emotions of the user.
The user’s choice of words gives a hint as to how the user was feeling when they wrote the post. For example, if they use words such as happy, good, and praise, then it indicates a positive feeling. However, sentiment analysis is far from straightforward: it can be thrown by sarcasm, double entendres, and complex sentence structure, so a good sentiment analysis algorithm should take sentence structure into account.
Companies often use sentiment analysis to observe customers’ reactions towards their brands whenever something new is implemented.
Simple texts can hold deep meanings and can point towards multiple subcategories. Mentions of locations, dates, locations, people, and companies can provide valuable data. The most powerful models are often very industry-specific and developed by companies with large amounts of data in their domain. A machine learning model can be trained to predict the salary of a job from its description, or the risk level of a house or marine vessel from a safety inspection report.
One cool application is forensic stylometry, which is the science of determining the author of a document based on the writing style. I’ve trained a simple forensic stylometry model with an online demo to identify which of three famous authors is likely to have written a text.

Forensic stylometry is an NLP technique that allows us to play detective to identify the author of a ghostwritten novel, anonymous letter, or ransom note. Image of Sherlock Holmes is in the public domain.
Natural language processing has also been helping with disease diagnosis, care delivery, and bringing down the overall cost of healthcare. NLP can help doctors to analyse electronic health records, and even begin to predict disease progression based on the large amount of text data detailing an individual’s medical history.
To name one commercial offering, Amazon Comprehend Medical is using NLP to gather data on disease conditions, medication, and outcomes from clinical trials. Such ventures can help in the early detection of disease. Right now, it is being used for several health conditions including cardiovascular disease, schizophrenia, and anxiety.
IBM has recently developed a cognitive assistant that acts like a personal search engine. It knows detailed information about a person and then when prompted provides the information to the user. This is positive step toward helping people with memory problems.
We have seen some examples of practical applications of natural language processing. Here we give a brief look into the most important NLP techniques, and the underlying stages of an NLP pipeline.
The bag of words model is the simplest model in NLP. When we run a bag of words analysis, we disregard the word order, grammar, and semantics. We simply count all the words in a document and feed these numbers into a machine learning algorithm.
For example, if we are building a model to classify news articles into either sport or finance, we might calculate the bag of words score for two articles as follows:
| Word | Article A | Article B |
| interest | 3 | 1 |
| goal | 1 | 2 |
| football | 0 | 2 |
| bank | 2 | 0 |
Example bag of words score for two articles which we want to assign to sport or finance.
Looking at the above example, it should be easy to identify which article belongs to which category.
The main drawback of the bag of words method is that we are throwing away a lot of useful information which is contained in the word order. For this reason, bag of words is not widely used in production systems in practice.
Tokenisation is often the first stage of an NLP model. A document is split up into pieces to make them easier to handle. Often, each word is a token, but this is not always the case, and tokenisation has to know not to separate phone numbers, email addresses, and the like.
For example, below are the tokens for the example sentence “When will you leave for England?”
| When | will | you | leave | for | England | ? |
This tokenisation example seems simple because the sentence could be split on spaces. However, not all languages use the same rules to divide words. For many East Asian languages such as Chinese, tokenisation is very difficult because no spaces are used between words, and it’s hard to find where one word ends and the next word starts. German can also be difficult to tokenise because of compound words which can be written separately or together depending on their function in a sentence.
Tokenization is also not effective for some words like “New York”. Both New and York can have different meanings so using a token can be confusing. For this reason, tokenisation is often followed by a stage called chunking where we re-join multi-word expressions that were split by a tokeniser.
Tokenisation can be unsuitable for dealing with text domains that contain parentheses, hyphens, and other punctuation marks. Removing these details jumbles the terms. To solve these problems, the next methods shown below are used in combination with tokenisation.
After tokenisation, it’s common to discard stop words, which are pronouns, prepositions, and common articles such as ’to’ and ’the’. This is because they often contain no useful information for our purposes and can safely be removed. However, stop word lists should be chosen carefully, as a list that works for one purpose or industry may not be correct for another.
To make sure that no important information is excluded in the process, typically a human operator creates the list of stop words.
Stemming is the process of removing the affixes. This includes both prefixes and suffixes form the words.
Suffixes appear at the end of the word. Examples of suffixes are “-able”, “-acy”, “-en”, “-ful”. Words like “wonderfully” are converted to “wonderful”.
Prefixes appear in front of a word. Some of the common examples of prefixes are “hyper-”, “anti-”, “dis-”, “tri-”, “re-”, and “uni-”.
To perform stemming, a common list of affixes is created, and they are removed programmatically from the words in the input. Stemming should be used with caution as it may change the meaning of the actual word. However, stemmers are easy to use and can be edited very quickly. A common stemmer used in English and other languages is the Porter Stemmer.
Lemmatisation has a similar goal to stemming: the different forms of a word are converted to a single base form. The difference is that lemmatisation relies on a dictionary list. So “ate”, “eating”, and “eaten” are all mapped to “eat” based on the dictionary, while a stemming algorithm would not be able to handle this example.
Lemmatisation algorithms ideally need to know the context of a word in a sentence, as the correct base form could depend if the word was used as a noun or verb, for example. Furthermore, word sense disambiguation may be necessary in order to distinguish identical words with different base forms.
Need a new NLP approach?

For many decades, researchers tried to process natural language text by writing ever more complicated series of rules. The problem with the rule-based approach is that the grammar of English and of other languages is idiosyncratic and does not conform to any fixed set of rules.
When I was working on our Clinical Trial Risk Tool, I needed to identify a number of key values from technical documents. One value that I needed was the number of participants in a trial. I tried to write a series of rules to extract the number of participants from a clinical trial protocol (the PDF document describing how a trial is to be run). I found sentences like the following:
We recruited 450 participants
The number of participants was N=231
The initial intention was to recruit 45 subjects, however due to dropouts the final number was 38
You can see how difficult it would be to write a robust set of instructions so that a computer can reliably identify the correct number.
So with this kind of problem, it’s often more sensible to let the computer do the heavy lifting. If you have several thousand documents, and you know the true number of participants in each of these documents (perhaps the information is available in an external database), then a neural network can learn to find the patterns itself, and recognise the number of subjects in a new unseen document.
I believe that this is the way forward, and some of the traditional NLP techniques will be used less and less, as computing power becomes more widely available and the science advances.
Common neural networks used for NLP include LSTM, Convolutional Neural Networks, and Transformers.
The field of natural language processing has been moving forward in the last few decades and has opened some meaningful ways to an advanced and better world. While there are still challenges in decoding different languages and dialects used around the world, the technology continues to improve at a rapid pace.
NLP has already found applications in finding healthcare solutions and helping companies meet their customers’ expectations. We can expect to see natural language processing affecting our lives in many more unexpected ways in the future. You can read more about business uses of natural language processing in our accompanying blog post.
Looking for experts in Natural Language Processing? Post your job openings with us and find your ideal candidate today!
Post a Job
This is an article based on my presentation on “The Role of Artificial Intelligence in Expert Investigations and the Preparation of reports” which I gave at the Expert Witness Conference on 20 May 2026.

Many companies and organisations have large datasets that are stored in a very unstructured format. For example, you could work for a US based healthcare provider or insurer and have patient records stored in a free text format such as HL7 files or PDFs. A building regulator, land registry, or mortgage provider may have texts and accompanying diagrams from thousands of building inspections or land title deeds. A patent attorney’s office may have records of patent applications in PDF format.

On 20 May, I attended the Expert Witness Conference in Dublin, Ireland, organised by La Touche Training. It was an eye opening event with a mixture of lawyers and expert witnesses in different fields from Ireland and abroad. The event was chaired by Mr Justice Michael Peart, with a keynote address by the Honourable Mr Justice David Barniville, President of the High Court of Ireland.
What we can do for you