
A tour of the challenges you encounter when using natural language processing on multilingual data.
Most of the projects that I take on involve unstructured text data in English only, but recently I have seen more and more projects involving text in different languages, often all mixed together. This makes for a fun challenge.
Recently I had a project that involved text in 12 languages, each of which bringing its own unique problems. I’d like to walk through some of their weird and wonderful things that you encounter when you try to build a system to do multilingual natural language processing.
In some areas of NLP, all available text is in a single language. An example would be a project processing scientific papers, which are now exclusively in English in the 21st century.
However, projects that involve non-formal communication across countries often involve text in a variety of languages. For example, a data science project in market research involving transcribed interviews from customers in different markets is likely to have unstructured text in different languages. Multinational marketing agencies would have datasets with questions such as how well do you think the packaging matches the product? asked in at least two varieties each of English, Spanish and Portuguese.
When our project is likely to have text in different languages, we have to be careful which NLP techniques we use. If we stick to models and toolkits that work well on English, we might be surprised when things stop working.
One of the simplest ways of building a natural language processing model is the bag-of-words approach. This means we reduce a text down to the words present in it, and we can use this to get a very quick and dirty similarity metric of two documents by counting the words they have in common.
If you have very short texts and a small amount of training data (and your text is in English!), the bag-of-words approach is great! It’s not so good with synonyms or inflections (think drive -> driving) but it does the job. For example if we want to compare two English sentences for similarity using a bag-of-words approach, we can do the following:
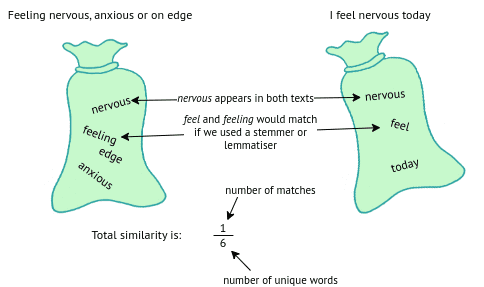
Bag-of-words for two English sentences
However, many languages have large numbers of suffixes that make the bag-of-words approach difficult.
If we want to compare similar texts in Turkish (Sinirli, kaygılı, endişeli misiniz = do you feel nervous, anxious or on edge, Endişeleniyorum = I feel nervous) we would immediately have a challenge, as no words are shared. Endişeleniyorum is “I feel nervous/worry” and endişeleniyoruz is “we feel nervous/worry”. In order to use a bag-of-words we would immediately need a Turkish stemmer or lemmatiser which would find the root of each word - but by replacing each word with its root we would lose vital information such as negation, tenses or pronouns.
This means that if you design a system to do any word-level comparisons (such as an information retrieval system or search engine), you will need to think about how to handle languages like Turkish and move away from simple word matching. I tried the above Turkish words in a Turkish stemmer in Python, to see if endişeleniyoruz and endişeli would be mapped to the same root, but they still weren’t (see code snippet below) - so even if you anticipate this issue in a highly inflected language such as Turkish it may not be easily solvable.
> pip install TurkishStemmer
Collecting TurkishStemmer
Downloading TurkishStemmer-1.3-py3-none-any.whl (20 kB)
Installing collected packages: TurkishStemmer
Successfully installed TurkishStemmer-1.3
> [python](https://www.python.org)
>>> from TurkishStemmer import TurkishStemmer
>>> [stemmer](https://tartarus.org/martin/PorterStemmer) = TurkishStemmer()
>>> stemmer.stem("endişeleniyoruz") # we worry
'endişeleniyor'
>>> stemmer.stem("endişeli") # anxious
'endişe'
>>> stemmer.stem("sürüyorum") # I am driving
'sürüyor'
>>> stemmer.stem("sürdüm") # I drove
'sürt'
German, Swedish and Dutch are famous for their long words made of other words glued together. But these can start to break NLP systems that were designed only for English.
Recently I had to solve this problem on a project for analysing text for a language learning app. For German I use a library called German Compound Splitter. As soon as German was added to the project, I had to install a separate package to split the compounds, and also include a German dictionary (which needed me to check its licencing conditions). Splitting compound words is a surprisingly hard problem because there may be multiple valid splits.
The word das Kernkraftwerk (the nuclear power plant) is an interesting case as it’s made of three nouns glued together:
das Kern = core/nucleus
die Kraft = power
das Werk = factory/work
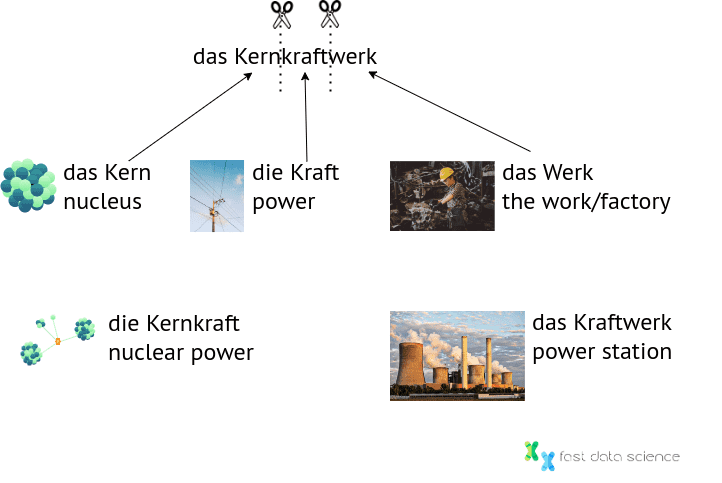
Do you want to split it into die Kernkraft + das Werk or das Kern + das Kraftwerk or even das Kern + die Kraft + das Werk? All would be grammatically valid, but it depends on what you want to use it for. I think I would go for Kern + Kraftwerk since a Kernkraftwerk (nuclear power plant) is a kind of Kraftwerk (power plant) and this would probably be the most informative splitting for most purposes - for example if you were searching a database for information about a Kraftwerk and there was an article about a Kernkraftwerk, it could still be of interest - although the inverse might not necessarily be true! One option would be to generate all splittings in order not to make the wrong decision.
You can try playing this very rudimentary German compound splitter below in your browser. It’s not as good as one which we could make with a neural network, but it’s fast and light weight. But I don’t promise it will get the right answers!
The challenges to do with making a German compound splitter include the fact that any implementation needs some form of a dictionary, to know which German words are valid single units and which ones need to be split further. The German dictionary is 6MB compressed and 30MB uncompressed, so this naturally makes any German compound splitter quite bulky. This is further complicated by the fact that the set of German words is open and includes proper nouns, which can sometimes be joined with suffixes, although usually with a hyphen for readability.
Initialising German dictionary...
Enter a German compound word and click 'Split Compound Word'.
For English, it’s quite straightforward to split a text into words. However as we’ve seen with the Turkish and German examples above, the information contained in a word is not always the same across languages. For some languages it can be hard even to split a sentence into words.
Hebrew and Arabic write articles and prepositions together, so “the computer” is written الكمبيوتر “alkumbyutar” and “by car” would be بالسيارة “bissayaara” where three words bi (by), al (the) and sayaara (car) are glued together.
However East Asian languages take this to another level. Chinese, Japanese and Thai are written without spaces at all, so the first stage in an NLP pipeline for these languages is a tokeniser, which uses machine learning to identify when one word ends and the next begins.
For English text, one factor that often comes up is text in UK and US variants. For example, if you have survey responses in both British and American English, and you want to highlight popular terms, if half of your users have written sanitise and half have written sanitize, this word’s popularity score will be reduced incorrectly if the system treats it as a single word.
I encountered this problem on a number of projects and I began to collect a set of rules to normalise all text either to British or American, which I’ve open sourced in a library called localspelling. It uses some generic rules (such as the -ise/ize suffix) combined with a dictionary-based approach, but words like program/programme are left untouched because there is too much ambiguity (as both variants exist in Britain).
Since I began working on a few projects with Brazilian Portuguese, I found that Portuguese has a similar set of spelling differences between Portugal and Brazil - I imagine that the same approach could be useful here.
There are some languages which have multiple writing systems. For example, Serbian can be written in Latin or Cyrillic, and there is mostly a one-to-one mapping between the two but not always (the Cyrillic system has slightly more information, so you can go unambiguously from Cyrillic to Latin but not vice versa).
Chinese has the simplified (mainland China) or traditional variant (Taiwan and Hong Kong), and Japanese has the Kana and Kanji representations of words.
For any language where your NLP system is likely to encounter text in different alphabets or writing systems, you will need to normalise to a canonical form. Each language with this problem will have a particular set of online tools that native speakers use (for example if a Chinese speaker wants to convert text from traditional to simplified), and there are also a set of APIs and libraries which do the substitution.
In most cases switching between writing systems is a case of letter-for-letter substitution with either some handwritten rules or some statistical or machine learning modelling to handle the edge cases. Most Chinese simplified characters have a single representation in traditional script, but some do have more than one. For example,
In simplified Chinese, the character 发 means either hair, or to send.
In traditional characters, 发 is written 發 when it means send, and 髮 when it means hair.
Fortunately there are several websites, Python libraries, and lookup tables which can do the conversion in either direction. The character 发 would never occur alone, but usually would be part of a two-character word such as 发送/發送 fāsòng (to send) or 頭髮/头发 tóufà (hair) - this means the disambiguation is easier than it sounds as it can be solved by some number-crunching.
However, some languages have a writing system that is so difficult for NLP that a whole neural network is required just to transcribe it…
Multilingual NLP
The most difficult NLP challenge I have found so far is Hebrew. To understand the pronunciation (for example, the romanisation) of a Hebrew word, you need to read the whole sentence. You can’t romanise a single word individually.
For example, the verb “want” is pronounced “rotzeh” if the subject is male and “rotzah” if female, but both are written the same way: רוצה . Vowels are usually not written down and to make things harder several consonant letters make the same sound, some make two sounds, and some are silent.
So a sentence like תומס רוצה (Thomas wants) is pronounced Thomas rotzeh
But חנה רוצה (Hannah wants) is pronounced Hannah rotzah.
Try moving the slider in the image below to see how much information is hidden in the vowels!


The sounds b and v are made with the same letter, differentiated only by an optional dot called a dagesh.
Because this system creates so much ambiguity, Hebrew has two optional systems of indicating pronunciation: the classical way, which involves adding dots and marks called nikkud inside, above and below letters, and a more modern way called ktiv maleh which involves inserting extra letters (vav and yod).
I was unable to find a simple Python import to romanise Hebrew. What I could find was a neural network called Nakdimon which runs as a Docker container, that can convert unvowelled Hebrew into Hebrew with nikkud and dagesh. I then had to write my own rules to convert the fully vowelled Hebrew into Roman letters. So in my deployed application Nakdimon is running on its own server. This means that Hebrew is the only language which needs an extra server (costing up to $50/month) just to interpret the alphabet!
I tried developing a Hebrew voweliser and romaniser (based on Nakdimon). This involved deploying a neural network to add vowel markings and then a separate rule-based step to Romanise the text. It was complicated! Here’s what it looked like:
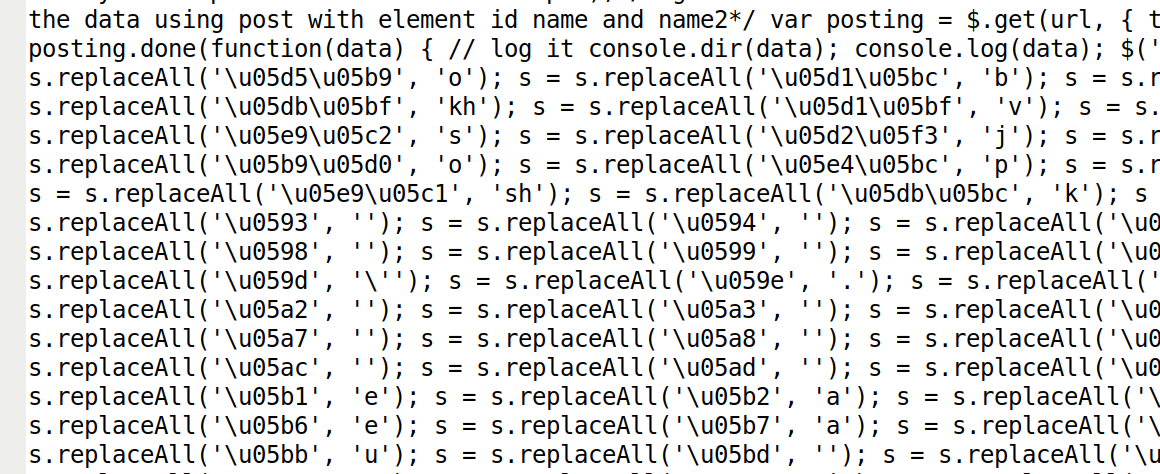
You can try a very basic (no neural network) Hebrew romaniser in the browser below. The text reads “I like data science”. You can see that without a smart neural network to fill in the vowels, the romanisation is practically illegible.
Click 'Transliterate' to see the result.
I will cover a few of the issues that arise at the point that you want to display text to a user, in a word cloud, graph or chart, and how you can troubleshoot these issues.
If you ever visited a non-English website in the early 2000s, you would have been familiar with garbled text encoding. If a file was created in a given set of rules to translate digits to letters, known as an encoding, and read by another user using a different encoding, then the result would be alphabet soup. Nowadays, this is less common but can still happen.
For example, the character encoding UTF-8, encodes the German letter Ü as two numbers: 195, 156. If you interpret the sequence 195, 156 using the UTF-8 encoding, you will get Ü (correctly), but if you read it using another encoding called Latin-1 (ISO-8859-1), you will get Ã\x9c, which is gibberish.
So a program reading text in the wrong encoding would display the German word “Übersetzen” (translate) as:
Ã\\x9cbersetzen
which is already hard to understand, and the Turkish word görüşürüz, would be displayed as:
görüÅ\\x9fürüz
In 1991, a group of tech companies founded the Unicode Consortium with the goal that text in any language can be correctly represented all over the world. Unicode is basically a list of every letter or character from every language in the world, with a number assigned to each one. So a lowercase a is character number 97, and the Hebrew letter א (aleph) is 1488, no matter what font is used.
The Unicode standard has solved the problem of alphabet soup, but not without controversy. Working groups from China, Taiwan and Japan debated hotly whose versions of each character would get primacy in the Unicode encoding. The result is that characters which are significantly different between countries have separate Unicode encodings, such as 囯 (22269) and 國 (22283) (both meaning country), while variants that have minor differences are assigned a single number and the choice of font determines how it will be displayed.

“Snow” (character 38634) displayed in font Noto Sans Traditional Chinese. Here is the character in whichever font your computer uses: 雪

“Snow” (character 38634) displayed in font Noto Sans Simplified Chinese. Here is the same character in whichever font your computer uses: 雪
Bizarrely, although the Unicode Consortium’s main achievement has been indexing the world’s writing systems and getting both sides of the Taiwan Strait to agree on it, Unicode seems to attract media interest only when they decide to add new emojis to the list! Thanks to Unicode, if you send somebody a Whatsapp with an emoji, it will also display correctly, even if the recipient has a different make of phone.
Nowadays, we can avoid alphabet soup by sticking to the UTF-8 encoding, which handles all alphabets. However, you have to be careful to always read and write files using UTF-8 encoding. For example, the below line of Python code for reading a file is dangerous because it may break if the file contains non-English text.
f = open("demofile.txt", "r")
and the correct way to read a file in Python is with the encoding specified always:
f = open("demofile.txt", "r", encoding="utf-8")
I recently had to develop a library to display multilingual word-clouds, and the problem that I encountered here was that there is no font that covers all languages. Even if you have your text in the correct language, you must also have a font with glyphs for that language. Some languages have rules about how the appearance of a letter should change depending on what’s around it, so those are handled by the font files. For example, the Arabic letter ة is displayed as ـة when it joins to a letter on its right - but whatever it’s displayed as, it always has the same encoding: 1577 (this is in accordance with Unicode’s principle that every character has only one encoding even if it can be rendered in a text as multiple glyphs).
I found a few useful font families which cover all languages. For example, Google Noto is a family of fonts covering many languages, and you can apply the correct flavour of Google Noto (often called “Google Noto [LANGUAGE NAME]”) depending on the language you want.
I put together a decision tree to help decide which font to use to display text in a given language:
| Language name | Is there a font for this language? | Choose font |
| English | Noto Sans English -> doesn’t exist | Noto Sans |
| Russian | Noto Sans Russian -> doesn’t exist | Noto Sans (this also has Cyrillic characters as well as Roman) |
| Arabic | Noto Sans Arabic -> exists | Noto Sans Arabic |
| Chinese (mainland) | Special rule:Noto Sans Simplified Chinese | Noto Sans Simplified Chinese |
| Gujarati | Noto Sans Gujarati -> exists | Noto Sans Gujarati |
To illustrate, this is what happens when I tried to display Arabic text in a Python word cloud without explicitly loading an Arabic font:

This is the same text with the font loaded but when the right-to-left logic is not correctly configured (so the letters are reshaped, joined together, but displayed in the wrong order):

And this is the text with the font correctly loaded:

One of the commonest problems that I see everywhere is no longer character encodings. This is presumably because you don’t need knowledge of a language to see when the encoding has completely broken: the text is displayed as squares or meaningless symbols instead of letters.
What’s far more common is for Arabic and Hebrew to be displayed with text reading in the wrong direction, and without the reshaping of letters. Quite often when I see Arabic text on a sign in an airport or shop, the text is displayed in the wrong direction, but since it looks the same to a non-speaker, it is often missed.
Fortunately, there’s an easy clue to check if bidirectional text display is working correctly. Both languages have letter forms which are only allowed at the end of a word, so if you see either of these final letters on the right, you know your text is the wrong way round.
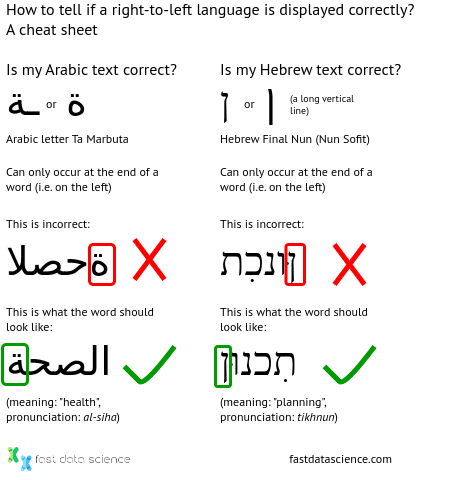
A cheat sheet for checking your text in a right-to-left language such as Arabic or Hebrew is being displayed correctly.
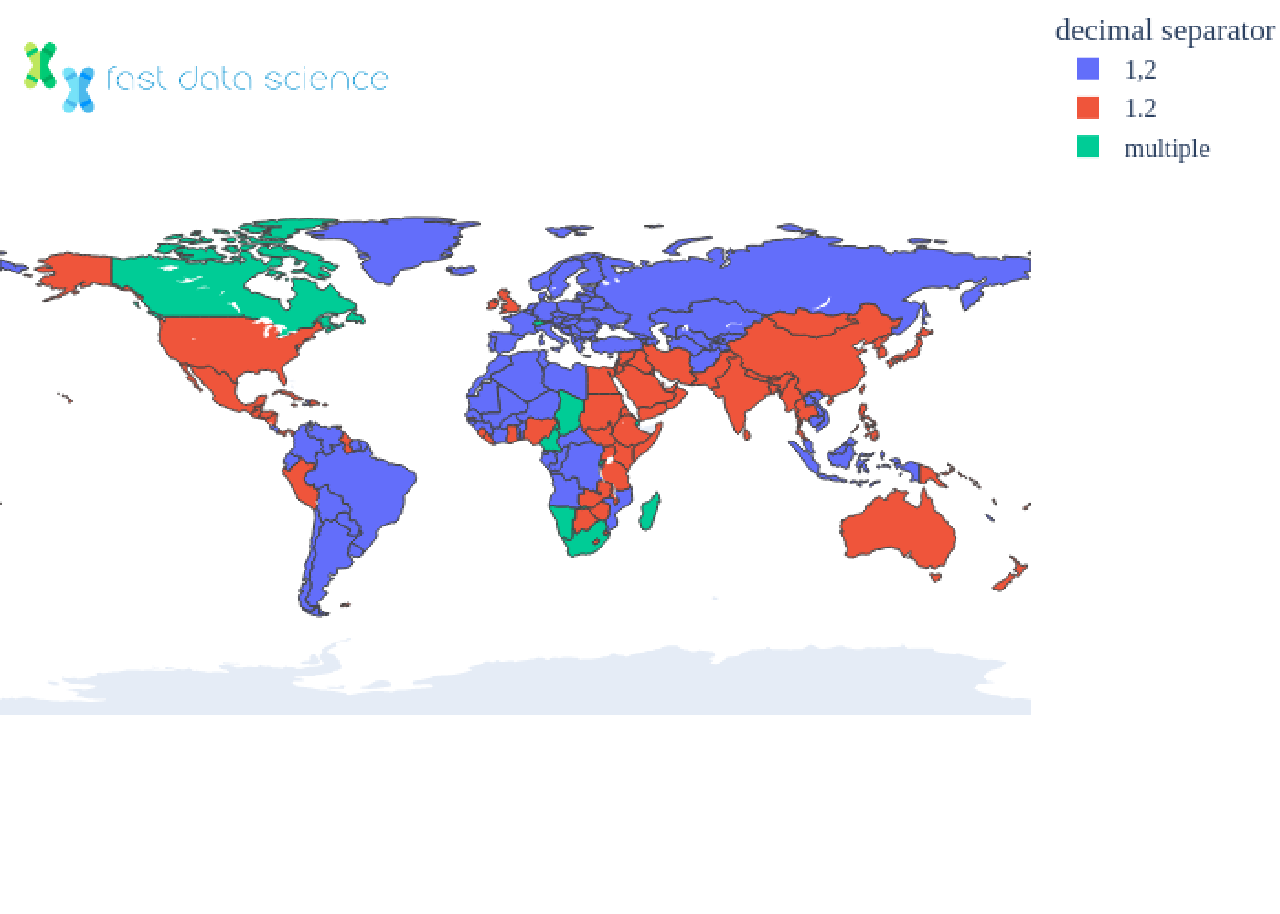
If you’ve ever transferred spreadsheets and CSV (comma-separated value) files between English and German computers, for example, you may have noticed some strange behaviour, and sometimes CSV files will fail to load. If a spreadsheet with a number such as 54.2 is saved as a CSV from an English-language Excel, and loaded into a German computer with the same version of Excel, the number may be incorrectly parsed. This is because different countries have different decimal separators and thousands separators, and in Germany the “.” is a thousands separator and the “,” is the decimal separator - the opposite of the English convention!
The number 12345.6 can be displayed as the following variants, depending on the locale:
| Countries | How the number could be displayed |
| UK, US | 12,345.6 |
| Germany | 12.345,6 |
| Switzerland | 12'345,6 |
| France | 12 345,6 |
In fact, different locales have many ways of handling decimals and thousands. Some countries use entirely different symbols, such as the Arabic decimal separator ٫, and in India, a comma is used at one thousand, a hundred thousand, and ten million.
Bilingual countries can have different conventions for different languages, and the same language can have variants for each country. For this reason, locales are normally expressed as a two-letter language code and a two-letter country code, e.g. de_DE means German as spoken in Germany.
What’s tricky about handling locales is that computers normally set the locale globally, on the level of the whole system. So if your computer is set to German, Excel will usually run in German. If you want to write a program to parse numbers in multiple locales, most examples I have found online involve setting the system locale, parsing a number, and setting it back.
Below you can see a breakdown of how different countries separate decimals and thousands:

One useful solution is the Python library Babel, which is built to deal with this kind of internationalisation headache. For example, the below snippet works shows how you can print a number in a variety of locales without changing the system locale:
import locale
from babel import numbers
print (numbers.format_decimal(12345.6, locale='de_DE')) # German (Germany)
# prints 12.345,6
print (numbers.format_decimal(12345.6, locale='de_CH')) # German (Switzerland)
# 12’345.6
print (numbers.format_decimal(12345.6, locale='fr_FR')) # French (France)
# prints 12 345,6
Instead of using separate packages and code to handle text in different languages, a new approach is gaining traction: there are models which are completely multilingual and have been trained on text in many languages. For example the Transformer model BERT is available in language-specific versions and a multilingual variant, BERT-Base-Multilingual.
These multilingual models handle text language-agnostically. If you use a package such as Microsoft NLU for building chatbots, you will find you are also able to upload training data in one language and run your chatbot in another - although in my experience the performance does go down slightly when you use a chatbot on a language it wasn’t trained on.
I did some experiments with Microsoft Language Studio. Microsoft claims that
“When you enable multiple languages in a project, you can train the project primarily in one language and immediately get predictions in others.”
Microsoft Azure Cognitive Services documentation
I put this to the test. I tried uploading English-only training data into my chatbot and tested it on Spanish text. I then tried training a chatbot on Spanish-only text, and on a mixture of Spanish and English text, to see which would be the best. I found that the Spanish-trained model performed the best, with the English model close behind.
In recent years, the size of language models has increased exponentially and since the release of ChatGPT in 2022, society has adapted to the widespread availability of conversational AI that is so good, that its output is often almost (but not quite) indistinguishable from that of a human. GPT, Gemini and other large language models are often capable of conversing in multiple languages, although their coverage of large world languages such as Spanish and Chinese is notably better than their coverage of languages with fewer speakers such as Hungarian or Xhosa. So for many business applications requiring multilingual capability, if you are using an LLM, you can often just plug and play - there’s no need to do anything different. It’s important, however, to anticipate that once you start feeding non-English text to GPT, the performance will degrade slightly.
There is a grassroots initiative to train transformer models for African languages, called Masakhane, which roughly translates to “We build together” in isiZulu. Masakhane’s initiatve is to strengthen NLP research in African languages. They have developed custom LLMs fine-tuned for several African languages. I tried downloading and evaluating their Shona model for the Harmony project and found it to perform adequately to the point that I was capable of assessing without being a Shona speaker myself.
We welcome any non-English or multilingual NLP projects, especially in under-resourced languages. Over the years we have deployed and run NLP models in Shona, Hebrew, Arabic, Portuguese, Spanish, German, Mandarin, Cantonese, Tagalog, Hindi (including non-standard Romanised Hindi). So whatever language your data is in, we are keen to hear from you.
Dive into the world of Natural Language Processing! Explore cutting-edge NLP roles that match your skills and passions.
Explore NLP Jobs
Unlock your business potential with expert AI consulting services from Fast Data Science. Discover strategies to accelerate growth and outperform competitors.

Financial advisors, like lawyers, are regulated in the UK. All financial advisors should be registered with the Financial Conduct Authority (FCA) and must have certain qualifications and have signed up to a code of ethics. UK financial advisors must also complete professional training every year.
What we can do for you
