
I have been working on the development of Harmony, a tool to help psychology researchers harmonise questionnaire items in plain text across languages so that they can combine datasets from disparate sources. One of the challenges put to us by Wellcome, the funders of the mental health data prize research grant for Harmony, was how well does Harmony handle culture-specific concepts? There is an idea in psychology of “cultural concepts of distress”, which is the idea that some mental health disorders manifest themselves in a particular way in different cultures.
Shona, or chiShona, is spoken mainly in Zimbabwe and belongs to the Bantu language family, along with Swahili, Zulu and Xhosa. An example of a “cultural concept of distress” is the Shona word “kufungisisa”, which can be translated as “thinking too much”.
Kufungisisa is derived from the verb stem -funga, to think, as follows:
| Shona | English |
|---|---|
| -funga | think |
| kufunga | to think |
| ndofunga | I think |
| -isa | (causative suffix: “to cause to do”) |
| -isisa | (intensive suffix: “to do quickly”) |
| kufungisisa | think deeply, think too much; a Shona idiom for non-psychotic mental illness |
Other examples of cultural concepts of distress include hikikomori (Japanese: ひきこもり or 引きこもり), a form of severe social withdrawal where a person refuses to leave their parents’ house, does not work or go to school, and isolates themselves away from society and family in a single room.
In order to see if we could match this kind of item using semantics and document vector embeddings, I had to look for a trained language model which could handle text in Shona. Luckily, there has been a project to train large language models in a number of African languages, and I was able to pass my Shona text through the model xlm-roberta-base-finetuned-shona trained by David Adelani at Google DeepMind and UCL. I found that the model was reasonably good at matching monolingual Shona text, but could not match mixed English and Shona text.
The Shona model that I found was developed as part of a paper by Alabi et al, where they developed LLMs for Amharic, Hausa, Igbo, Malagasy, Chichewa, Oromo, Naija (Nigerian Pidgin English), Kinyarwanda, Kirundi, Shona, Somali, Sesotho, Swahili, isiXhosa (Xhosa), Yoruba, and isiZulu (Zulu) - as well as afro-xlmr-large which covers 17 languages.
In particular, to handle the challenges of lack of resources for certain languages, the researchers used language adaptive fine-tuning (LAFT), which involves taking an existing multilingual language model and fine-tuning it for the target language.
You can read a write up of my experiments with the Shona model here, and you can download my code in a Jupyter notebook here.
I would be curious to find out how well culture-specific concepts can be represented by embeddings, but I do not have a definitive answer yet, as multilingual LLMs are still in their early stages.
Looking for experts in Natural Language Processing? Post your job openings with us and find your ideal candidate today!
Post a Job
Fast Data Science Ltd’s flagship AI platform, the Clinical Trial Risk Tool, has been accepted as a supplier on the UK Government’s G-Cloud 15 framework.

We are pleased to announce that Thomas Wood, director of Fast Data Science, will be appearing as a panelist at the Bond Solon Expert Witness Conference on 6 November 2026 at Church House, Westminster in London. This follows Thomas’s recent appearance at the Ireland’s Expert Witness Conference on 20 May 2026.
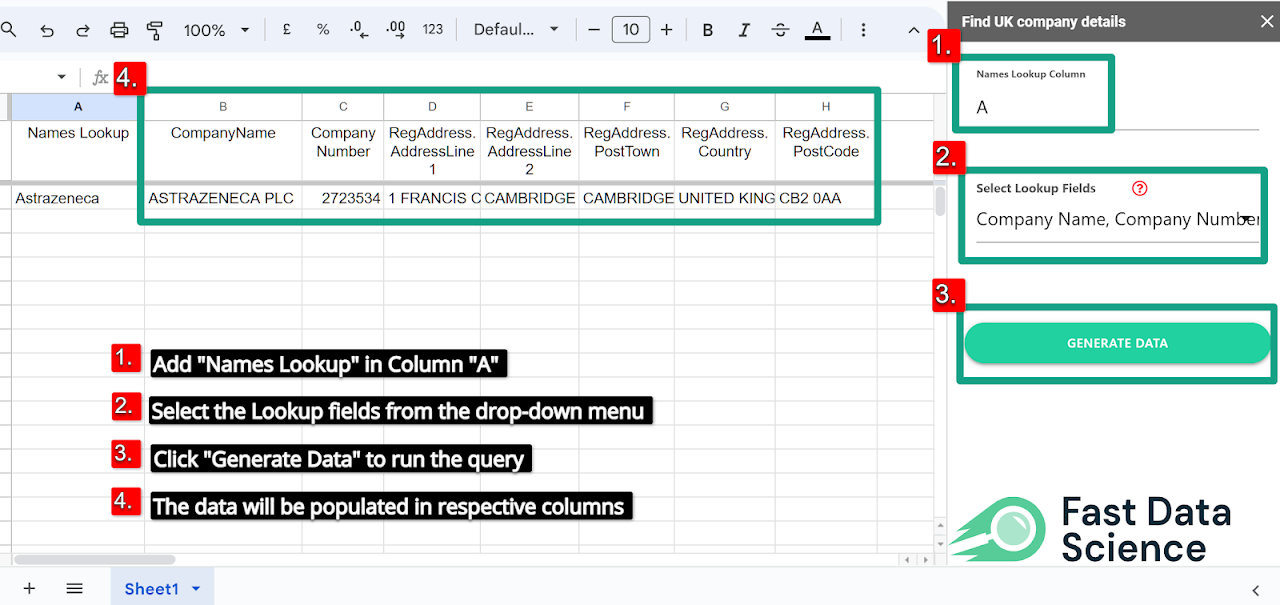
Fast Data Science are pleased to announce we have updated the UK Company Details Google Sheets™ plugin. The plugin allows you to retrieve details such as company number, incorporation date, address, and directors’ details from Companies House (the UK company registry) and automatically populate them in columns of a Google Sheets™ spreadsheet.
What we can do for you