
Open source software is software that is made freely available to the public. It is typically developed and maintained by a community of developers who collaborate to improve the software and make it available for anyone to use, ideally with no strings attached.
Open source software is often seen as an alternative to proprietary software, as it is usually free to use and modify. The rules about what you’re allowed to do with open source software (e.g. are you allowed to make money with it) are set out in a document called the licence. Some of the most popular open source licences are the MIT License and the Apache License, which both permit a user to modify software and use it in commercial applications.
An open-source, NLP and generative AI-driven tool for harmonising questionnaire items, even across different languages, developed for the Wellcome Data Prize in Mental Health. Try Harmony online.
Learn More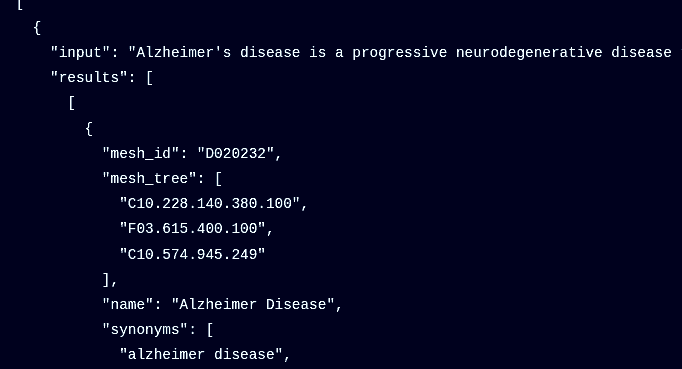
An open-source Python library for finding medical conditions and diseases in text and returning MeSH codes. Essential for clinical named entity recognition and linking tasks.
Learn MoreAn open-source Python library specifically designed for recognizing drug names in unstructured English text, facilitating named entity recognition and linking for AI in pharma applications. The library has also been integrated into a handy Google Sheets plugin.
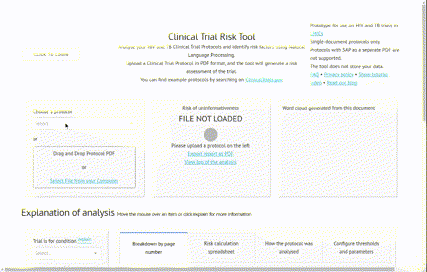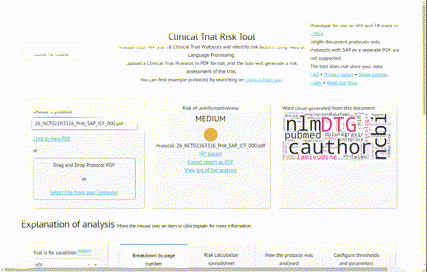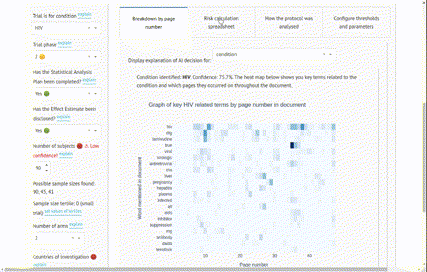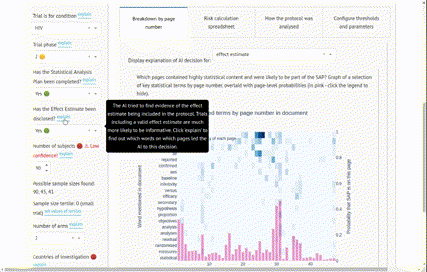
Learn MoreA Natural Language Processing-powered tool developed for the Bill and Melinda Gates Foundation, assisting experts in estimating the risk of a clinical trial ending uninformatively. The Clinical Trial Risk Tool also reads a clinical trial protocol and creates an itemised per-subject budget from the schedule of events, looking up costs in hospital charge masters. Try the Clinical Trial Risk Tool.
Learn More
An open-source Python library to identify country names within English text, enabling country named entity recognition and linking for various NLP tasks.
Learn More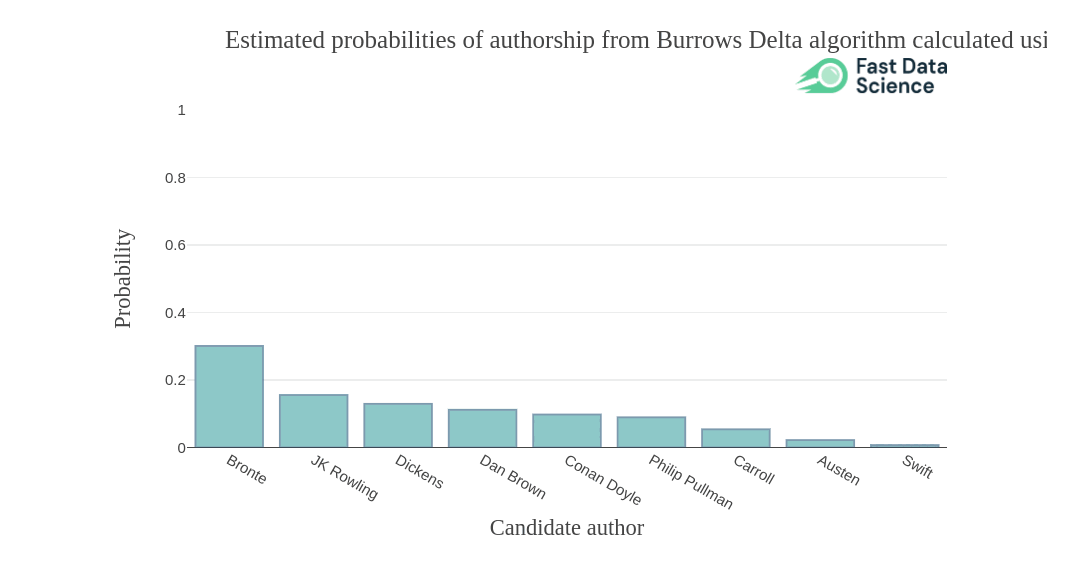
A unique forensic stylometry model that identifies the author of a text by their stylistic and linguistic "fingerprint," requiring a relatively long text for accurate identification.
Learn MoreOpen source software has become increasingly important in natural language processing, as NLP systems are becoming more complex and reaching into more and more fields of our lives, from household uses, to applications in industries such as pharmaceuticals, such as drug discovery, or clinical trial risk management. Open source natural language processing tools allow developers to collaborate to create innovative solutions to problems in natural language processing, and can help to reduce the cost of developing natural language processing systems.
An ideal open source project is a public good and people may contribute to it to gain experience, to add to their portfolio and be more attractive to employers, or because the topic is an area of passion for them. Contributors on open source projects can be motivated by extrinsic factors or pure altruism.[1]
At Fast Data Science we have worked on several open source NLP projects in fields from psychology to pharmaceuticals. All our projects use the MIT License.
You can find the source code of all our open source NLP projects either on our Github account or on the page for the Harmony project.
Fast Data Science - London
It should be pointed out that models such as OpenAI’s GPT API, Google Vertex, and commercial offerings by tech giants are usually closed source. These can be convenient to get started with and may come with dedicated support from the vendor, but usually there will be a cost such as a licence fee.
We have taken a lead role in developing a number of open source NLP projects, which are available to the public for personal and commercial use. These are all under the MIT License, which allows anyone to use our code for commercial purposes without an obligation to make their derivative work also open source.
Interested in other open source libraries? Find out about the third party open source libraries that Fast Data Science recommends here!
(Github repo) - Harmony is a tool and research project using natural language processing to harmonise mental health data. Read more at https://harmonydata.ac.uk and try the demo at https://harmonydata.ac.uk/app/. Funded by the Wellcome Trust and adhering to the MIT license and FAIR data principles.
(Github repo) - a tool using natural language processing to categorise clinical trial protocols (PDFs) into high, medium or low risk. Read more at https://clinicaltrialrisk.org/ and try the demo at https://clinicaltrialrisk.org/tool.
In addition to the externally funded projects above, we have developed some open source NLP tools aimed at Python developers.
A lightweight Python library for recognising drug names in unstructured text and performing named entity linking to DrugBank IDs.
The Drug Named Entity Recognition package allows you to identify drug names in an English text and find identifiers (MeSH, Drugbank, NHS) and even returns the molecular structure of a drug! It’s also available as a Google Sheets plugin.
Install with:
pip install drug-named-entity-recognition
A similarly lightweight Python library for recognising clinical terminology in unstructured text and performing named entity linking to MeSH IDs.
The Medical Named Entity Recognition package finds clinical terminology and maps to the Medical Subject Headings (MeSH) thesaurus.
Install with:
pip install drug-named-entity-recognition
Localspelling is a library for localising spelling between US and UK variants. Install from the command line with pip install localspelling
This is a lightweight Python library for recognising country names in unstructured text and returning Pycountry objects. Tutorial here.
Install with:
pip install country_named_entity_recognition
Cite as:
Alisa Redding at the University of Helsinki used the tool for her Masters thesis on mass species extinction and biodiversity.
Fast Stylometry is a Python library for forensic stylometry. Read tutorial.
Install with:
pip install faststylometry
There are many free and open source (FOSS) tools available for natural language processing purposes. Which one you choose for a project depends on the precise use case.
| Tool | Licence | Summary |
|---|---|---|
| spaCy | MIT | spaCy is a great all-round tool for NLP projects. You can use it for rule-based and pattern-based matching, training text classifiers, custom named entity recognition models, embeddings and transformers, and extracting grammatical relations. We are using spaCy inside our Clinical Trial Risk Tool |
| Natural Language Toolkit (NLTK) | Apache 2.0 | NLTK is a great platform for processing text with Python. It pre-dates neural networks, so it does a lot of “traditional” NLP such as tokenising, stemming, stopwords, dictionaries, etc. It also comes with corpora to import. |
| Sentence Transformers at HuggingFace | Depends on model | HuggingFace has provided an easy interface to the sentence transformers models, allowing you to run an LLM on your PC in a few steps. We are using HuggingFace Sentence Transformers as the backbone of the Harmony project (more information below). |
| Scikit-Learn | BSD 3-Clause | A fantastic all-round machine learning library in Python which has some really useful simple classifiers such as Naive Bayes, which can be built as part of a pipeline and serialised and deserialised. |
Here’s an overview of when you might want to use the big tools mentioned (we are only covering Python tools in this article). You can really give your NLP project a head start by choosing the appropriate open source NLP tool as a foundation!
| Use case | Tool |
|---|---|
| Language learning app needing to find grammatical structure in sentences | spaCy |
| Simple low-footprint text classifier e.g. email triage on a serverless app, which doesn’t need to be very sophisticated. Text is in a single language. There are a small number of categories e.g. <10, you may not have a huge amount of data, and the categories are easily separable by presence/absence of key words, e.g. economics vs sport (as opposed to “longitudinal studies in psychology” vs “cohort studies in psychology” which would be much harder to distinguish) | Scikit-Learn |
| Sophisticated text classifier which needs to take into account context of words in sentence; smart AI tool which psychologists can use to compare text data or find similar documents | Sentence Transformers at HuggingFace |
| Analysis of N-grams in a corpus, finding clusters in unstructured documents | Natural Language Toolkit (NLTK): this library has a great implementation of Latent Dirichlet Allocation |
Open data and FAIR data principles are two important concepts in the data sharing and data management world. Open data refers to data that is freely available and accessible to the public. The FAIR data principles are a set of guidelines published in Nature in 2016, aiming to ensure data is Findable, Accessible, Interoperable, and Reusable.
Fast Data Science, a pioneer in natural language processing solutions, champions open-source innovation since 2016. Our natural language processing solutions empower businesses to extract insights from unstructured text, leveraging open-source natural language processing tools like NLTK and spaCy. These nlp tools enable efficient processing of text data, from tasks like sentiment analysis to entity recognition, driving cost-effective outcomes for clients in healthcare, legal, and more. The natural language processing solutions we specialise in integrate seamlessly with platforms like AWS, ensuring scalability and accessibility.
For instance, we’ve developed NLP tools for projects like the Clinical Trial Risk Tool, automating complex document analysis. Our commitment to open-source fosters transparency and collaboration, allowing businesses to customize natural language processing tools for specific needs.
Since 2016, led by Thomas Wood with a Cambridge Masters in NLP, Fast Data Science has delivered robust nlp tools that address challenges like multilingual processing and data privacy. Our natural language processing solutions provide user-friendly interfaces and actionable insights, enhancing decision-making.
Contact us to explore how our natural language processing solutions and nlp tools can transform your data, boosting efficiency and innovation in a data-driven world.
new_lines Please raise an issue in the Github issue board for the respective library. Please include all information about what you did, what the input was, and what went wrong. We need to be able to reproduce the error which you encountered. Then we will investigate the issue and hopefully we can fix it or provide the necessary support.
Please raise a pull request in the appropriate library. We appreciate if you can keep your modifications to a minimum. That is, please ensure that you’re not pushing files which you don’t need to change. Ideally your pull request will only modify 2 or 3 files, otherwise it could be made more atomic. Here is a guide on making a good pull request: https://harmonydata.ac.uk/open-source-for-social-science/contributing-to-harmony-nlp-project/#forking-and-submitting-a-pull-request-pr
All of our open source libraries have a DOI and citation information in the README and CITATION.cff files. However, if you find one that is missing please use the contact form on fastdatascience.com.
For example, in the case of the Drug Named Entity Recognition library (https://github.com/fastdatascience/drug_named_entity_recognition), a citation could look like this:
Wood, T.A., Drug Named Entity Recognition [Computer software], Version 2.0.9, accessed at https://fastdatascience.com/drug-named-entity-recognition-python-library, Fast Data Science Ltd (2024)
You can use a Bibtex format which can be imported and converted into many citation formats:
@unpublished{drugnamedentityrecognition,
AUTHOR = {Wood, T.A.},
TITLE = {Drug Named Entity Recognition (Computer software), Version 2.0.9},
YEAR = {2024},
Note = {To appear},
url = {https://zenodo.org/doi/10.5281/zenodo.10970631},
doi = {10.5281/zenodo.10970631}
}
Again, please check the README and CITATION.cff and if this information is missing or incorrect please let us know. And thank you very much for remembering to cite us! Your citations help us keep our open source projects alive.
What we can do for you





