In natural language processing, we have the concept of word vector embeddings and sentence embeddings. This is a vector, typically hundreds of numbers, which represents the meaning of a word or sentence.
Embeddings are useful because you can calculate how similar two sentences are by converting them both to vectors, and calculating a distance metric.
You can see below how two sentences can be converted to a vector, and we can measure the distance between them. Try playing with a few sentences in the Fast Data Science Sentence Embeddings Visualiser below - it’s really interesting to get some intuition for how vector embeddings behave. It may take about 30 seconds to load the transformer model. The model runs in your browser, which means it’s not the biggest or most powerful model out there!
--
--
The above example uses the Universal Sentence Encoder lite in Tensorflow JS, which runs in your browser and doesn’t send anything to a server. It uses vectors of size 512 (512-dimensional embeddings).
Before embeddings, if you wanted to compare documents or texts to work out how similar they were, the easiest way was to count the words in common. This clearly falls over when documents don’t share any words in common, but use synonyms. You can read about ways of comparing text in our blog post on finding similar documents in NLP.
Sentence embeddings mean that your entire document set can be converted to a set of vectors and stored like that, and any new document can be quickly compared to the ones in the index.
In the Harmony project, we’ve developed an online tool which allows psychologists to compare questionnaire items semantically to identify common questions among questionnaires. Harmony calculates that a question such as “I feel nervous” might be 78% similar to one such as “I feel anxious”. This value is just the cosine similarity metric (the similarity between two vectors) expressed as a percentage!
*You can try the Harmony app at harmonydata.ac.uk/app.
Sentence embeddings are often used in Retrieval Augmented Generation (RAG) systems: if you want to use a generative model such as ChatGPT, but give it domain specific knowledge, you can use sentence embeddings to work out which bit of your knowledge base is most relevant to a user’s query.
We have used RAG in the Insolvency Bot project, a chatbot with knowledge of English and Welsh insolvency law. When the user asks the Insolvency Bot a question, we convert it to an embedding, and we might identify that their question is about cross-border insolvency. We then send the parts of the Insolvency Act 1986 which are relevant to cross-border insolvency, together with the user’s query, to OpenAI, and retrieve a bot response which is much better than what GPT would have done on its own without any additional context.
Two of the commonest ways of calculating the similarity between two sentence or word embedding vectors are the Euclidean distance and the cosine similarity. These are easier to understand in two dimensions.
Let’s imagine you want to compare two dissimilar sentences, and two similar sentences. If we imagine our vectors are only in two dimensions instead of 512 dimensions, our sentences might look like the below graphs.
The Euclidean distance (see the two graphs below) is just the straight-line distance between the two vectors. It is large when the two sentences are very different and small when they are similar.
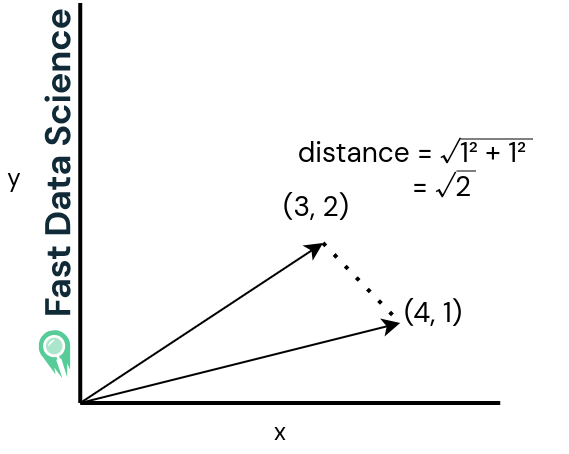
The Euclidean distance for two vectors which are close together is small.
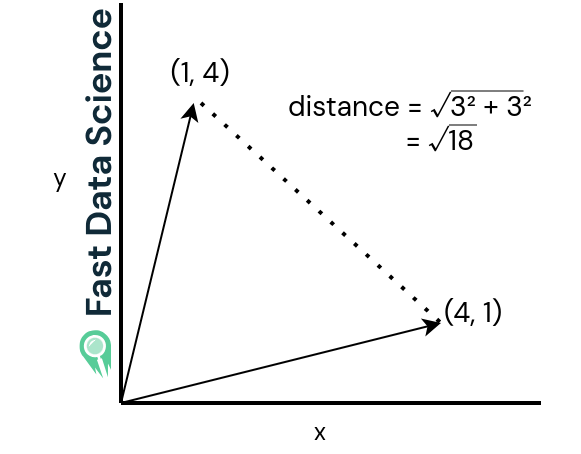
The Euclidean distance for two vectors which are pointing in more different directions.
The cosine similarity (bottom two graphs) is a value between -1 and 1 and it’s the dot product (scalar product) of the two vectors, divided by the dot product of their lengths. For vectors of length 1, it’s the same as the dot product of the two vectors (you don’t need to divide by anything).
Similar sentences have a cosine similarity close to 1, whereas very different sentences have a similarity close to 0 or even negative. It’s quite rare to see cosine similarities that are close to -1.
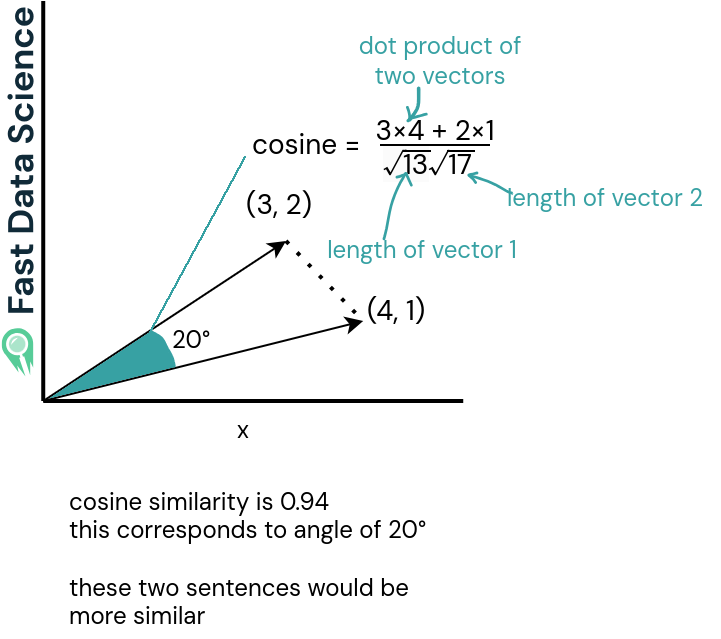
The cosine similarity is large or close to 1 for two vectors which are pointing in a similar direction, indicating semantic similarity.
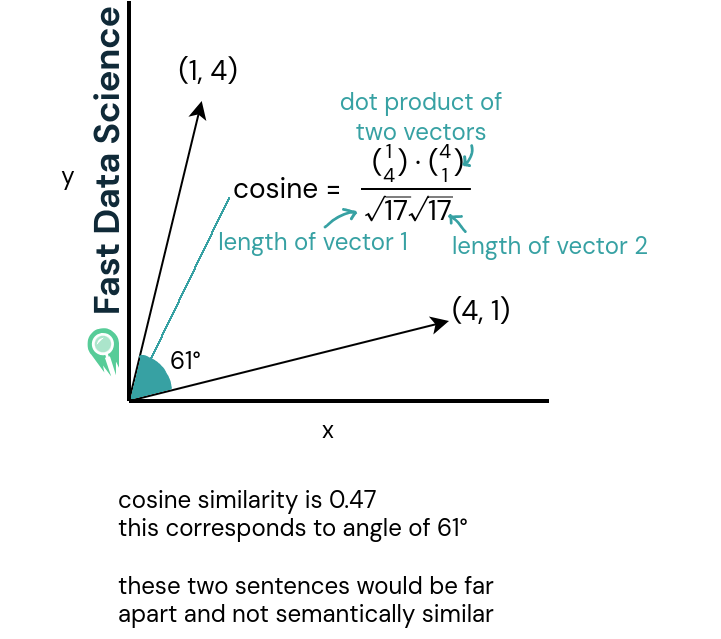
The cosine similarity for two vectors which are pointing in very different directions is small. For vectors pointing in opposite directions, it would be negative.
Most sentence embedding models such as the HuggingFace transformer models give all vectors of length 1, which means that you don’t need to calculate the bottom half of the fraction in the formula for the cosine similarity.
In the demonstration at the top of this page, we are calculating the cosine similarity.
Semantic similarity with NLP
I have a walkthrough on how you can fine tune your own large language model for sentence similarity, with an accompanying video tutorial and downloadable data and scripts:
T. Mikolov et al.. Efficient Estimation of Word Representations in Vector Space, arXiv:1301.3781 (2013)
Reimers and Gurevych, Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (2019).
Cer et al. Universal sentence encoder (2018).
Ribary, M., Krause, P., Orban, M., Vaccari, E., Wood, T.A., Prompt Engineering and Provision of Context in Domain Specific Use of GPT, Frontiers in Artificial Intelligence and Applications 379: Legal Knowledge and Information Systems, 2023. https://doi.org/10.3233/FAIA230979
Ready to take the next step in your NLP journey? Connect with top employers seeking talent in natural language processing. Discover your dream job!
Find Your Dream Job
This is an article based on my presentation on “The Role of Artificial Intelligence in Expert Investigations and the Preparation of reports” which I gave at the Expert Witness Conference on 20 May 2026.

Many companies and organisations have large datasets that are stored in a very unstructured format. For example, you could work for a US based healthcare provider or insurer and have patient records stored in a free text format such as HL7 files or PDFs. A building regulator, land registry, or mortgage provider may have texts and accompanying diagrams from thousands of building inspections or land title deeds. A patent attorney’s office may have records of patent applications in PDF format.

On 20 May, I attended the Expert Witness Conference in Dublin, Ireland, organised by La Touche Training. It was an eye opening event with a mixture of lawyers and expert witnesses in different fields from Ireland and abroad. The event was chaired by Mr Justice Michael Peart, with a keynote address by the Honourable Mr Justice David Barniville, President of the High Court of Ireland.
What we can do for you