
Does protecting sensitive data mean that you also need to compromise the performance of your machine learning model?
If you study machine learning in university, or take an online course, you will normally work with a set of publicly available datasets such as the Titanic Dataset, Fisher’s Iris Flower Dataset, or the Labelled Faces in the Wild Dataset. For example, you may train a face recognition model on a set of celebrity faces that are already in the public domain, rather than private or sensitive data such as CCTV images. These public datasets have often been around a very long time and serve as useful benchmarks that everyone agrees on.
 models](https://fastdatascience.com/images/machine_learning_sensitive_data_titanic_dataset_table-min.png)
The Titanic dataset
The Titanic Dataset is a well-known dataset for practising machine learning. We can use sensitive personal data about the passengers because the Titanic sank so long ago.
However, in a commercial setting, we often have to train machine learning models from private or sensitive data. With the exception of new startups, large companies may have databases of extremely personal data, such as millions of people’s addresses, social security numbers, financial information, healthcare history, or more. Companies are extremely reluctant to allow access to this kind of data when it is not strictly necessary. This presents a problem for a data scientist who needs to train a model on sensitive information. Some machine learning projects are simple in a technical sense but complicated immensely by data protection obligations.
Let me present an example from our own portfolio. We recently developed an NLP model for a large client in the UK which receives thousands of customer emails per day. The client wanted an email triage system so that customers with some of the common queries (such as a change of home address) could be automatically directed towards a web form that would resolve their query. The plan was to reduce the workload of the customer service staff, and free up their capacity for non-routine queries.
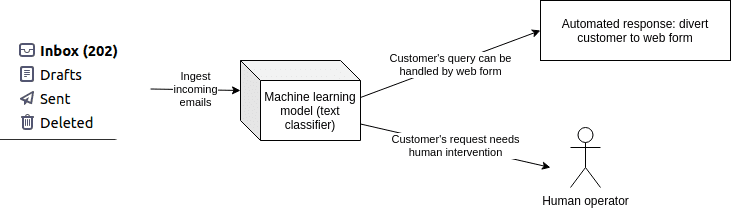
How an AI email triage system works: incoming emails are classified according to customer intent, and those customers who can solve their problem with a simple web form are directed to the correct form. This requires sensitive data detection, and while it is technically simple to build but tricky because of the sensitive data needed to train the model.
On the face of it, this problem is technically quite straightforward: you need to take a sample of emails, annotate them manually, and then train a text classifier and deploy it. However, due to data protection legislation, we needed to consider the following:
the users have not consented for their emails to be stored. If I manually annotate a training dataset (a time-consuming process), I cannot store it indefinitely. It must be deleted.
if under the GDPR’s right to be forgotten, a user can request that the organisation delete all of their personal data. If a user were to submit such a request, how would I track down all places that the personal data has permeated to in the machine learning pipeline? It must be possible to trace all copies of an email in all datasets.
the dataset cannot leave the client’s computer systems. I cannot download a file to my computer and experiment with different machine learning models. All model development must take places on servers controlled by the client.
can any sensitive data be reproduced from the model? For example, if a customer’s email address was stored in an NLP model as a word in its vocabulary, then some customer data has polluted the model. We must take care to ensure that nobody could reconstruct any sensitive information from a trained model.
The data subject shall have the right to obtain from the controller the erasure of personal data concerning him or her without undue delay
A risk that is sometimes overlooked is that a machine learning model could accidentally memorise sensitive parts of its training data. In 2017 a team at Cornell University/Cornell Tech trained a number of face recognition deep learning models on celebrity faces. They were then able to extract the original face images from the neural network, albeit with the quality slightly degraded.
With their technique, an adversary with access to a trained machine learning model that has learnt to detect and classify sensitive data could potentially reconstruct a part of that data. For example, a machine learning model that has learnt to classify jobseekers’ CVs (résumés) may have stored tokens specific to individuals’ names, or react unusually to a particular character combination in an address, allowing a route in for a malicious attacker to deduce the address that appeared in the training data.
There is a number of strategies that a data scientist can pursue in the face of extremely challenging data privacy requirements.

For the duration of the project, annotated data can be used. Only one copy of the dataset can exist. However, once the machine learning model has been trained, the data scientist must delete the complete dataset.
Deleting all your annotations means you are “throwing away the mould”: if the project were to resume in future, you would need to re-annotate a new dataset. However, if all data is truly deleted, then there is no way that the data can leak, and the “right to be forgotten” is no longer an issue.
We can attempt to make a non-sensitive dataset. For example, we process all emails using a data anonymisation algorithm to remove names, addresses or other sensitive information. This means that our dataset becomes a scrubbed set of emails, with no personally identifiable information left in.

Once an email has been anonymised and all sensitive data removed, what remains may not be sufficient to train an accurate machine learning model.
There are a number of third-party products which can be used to anonymise text. For example, Anonymisation App, or Microsoft Azure Text Analytics.
The risk of this approach is that text anonymisation is difficult, time-consuming, and it is possible to accidentally leave a sensitive piece of information in. In addition, the anonymised dataset may be too far from the real thing to produce the most accurate model.
On the plus side, if no sensitive data goes anywhere near the machine learning model, it cannot remember anything it shouldn’t, and it will not be possible for an attacker to reconstruct the sensitive information by poking the model, which helps sensitive data detection.
You may be able to annotate the data and then delete it, storing only a hash or ID of the original information, so that the training data can be easily reconstructed but it is not stored in your machine learning system. For example, you may choose to store the ID of each email and the label of each email, so that the training data can be re-built provided the emails have not been deleted from the email server. This means that the machine learning project does not rely on any extra copies of data.
If you store hashes of email addresses, you need to be cautious, because if a hacker got hold of your hashed database as well as a database of email addresses from another company, they could hash all those email addresses and cross check them against your database, and reconstruct the original email addresses.

How emails can be hashed. The email address jefod50602@yncyjs.com is converted to the string c379bd7a05f1af4522d5ad28af10d623 by a hashing algorithm. This can’t be easily reversed, but a hacker who got hold of another list of emails (such as the Ashley Madison data breach) could apply the same hashing function to that list, and identify the original email in the dataset.
Another approach is to obtain permission to hold customer data for longer and to use it for training an AI. This may not always be an option, but if enough customers consent, we may be able to build a training dataset only from the consenting customers. We must be careful, however, as consenting customers may not be representative of the entire customer base (they may spend more, spell better, belong to a different demographic group, etc), and this could introduce a bias into our trained model. In addition, this strategy would normally only work going forward with new customers, but a company may want to use the entire existing customer base for training their machine learning model.
 left index fingerprint showing some minutiae](https://fastdatascience.com/images/Thomas-Wood-left-index-fingerprint-showing-some-minutiae-min.jpg)
My left index fingerprint showing some minutiae (feature points such as junctions or culs-de-sac). The minutiae coordinates could then be encrypted or transformed according to a one way process, allowing machine learning on obfuscated data.
It is sometimes possible to obfuscate a sensitive dataset in such a way, that the sensitive data can’t be reconstructed, but machine learning can still learn from it. This is called homomorphic encryption. For example, a biometric fingerprint dataset could be converted into a set of minutiae (feature points), which could then be transformed by a non-reversible operation. The operation would have the property that fingerprints which are similar in real life, remain similar after encryption, but the encryption still cannot be reversed.
Homomorphic encryption is often very hard to do. A simple way of achieving the same result is to transform numeric fields using Principal Component Analysis. For example, a transformed value could be 2 * age + 1.5* salary + 0.9 * latitude, which would be very hard to map back to an individual due to the many-to-one nature of the transformation.
In addition to ensuring that no data is copied unnecessarily, or checked into repositories, there are other routine security measures which need to be taken in the case of sensitive training data. For example, any API endpoints must be secured with SSL and HTTPS, and you should not share data over third party services such as Github or Gmail.
You may find that a particular field, such as date of birth, is highly sensitive but contributes little to the model accuracy. In these cases there is a tradeoff between security, and machine learning model performance, and there may be a business decision to sacrifice accuracy in order to maintain good data governance.
Data can be altered, or coarsened, so that it is still of use for machine learning, but the potential for identifying sensitive data is reduced. For example, latitude/longitude locations can be rounded or jittered, postcodes (W9 3JP) can be reduced to the first half (W9), and numeric quantities can be binned. The USA’s HIPAA regulation specifies that in certain circumstances ages should be stored only as years rather than dates, unless if the age is over 90 in which case the year should also be hidden.

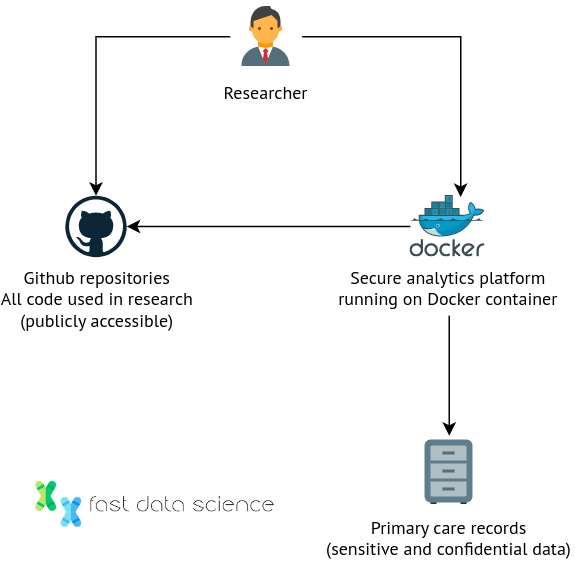
It is also possible to keep the sensitive data in a safe repository where researchers cannot access it directly, but they can submit experiments to it and perform statistical tests. The National Health Service (NHS) in England has set up a pilot program called OpenSAFELY, which allows researchers to use 58 million people’s health records without ever seeing them. Users can write code and submit it on the platform (downloadable as a Github repository), without ever needing to view the raw records. All interactions with the data are logged, and approved projects are listed on OpenSAFELY’s website.
How does this work in practice? OpenSafely uses a set of tiered tables and researchers don’t have the access to run simple database queries and see the raw data. The architecture is centred around a secure analytics platform where code is executed, but the code itself is pushed to public Github repositories by researchers.
OpenSAFELY embodies an innovative way of conducting research on sensitive data which arose during the early days of the pandemic. Dr Ben Goldacre, director of the University of Oxford’s EBM Data Lab, described this as a shift from models based on trust (researchers are trusted to keep data secure), to models based on proof.
I was curious to find out if I could also experiment on the text content of health records using OpenSAFELY’s platform. Of the 151 projects listed on OpenSAFELY’s website, none are text related (most appear to be studies of more structured data, such as “The impact of COVID-19 on pregnancy treatment pathways and outcomes”). I contacted OpenSAFELY and asked if it is possible to run experiments on text data, and they replied that they aren’t doing text projects at the moment. I would be intrigued to imagine how the OpenSAFELY model could be extended to allow experimentation on text data.
One rather drastic option to protect sensitive data which I have heard of used in health tech and med tech is to take a clean laptop, install all analytics software onto it, and then transfer the sensitive data onto it and physically remove all Internet connectivity. Now only the results of analyses, or machine learning models, can leave the laptop, and the laptop does not leave the premises of the institution, such as a hospital, where the model is being trained. Researchers sometimes use this approach when developing models on electronic health records (EHRs). For example, if there is no secure way of anonymising an EHR if it’s in plain text, we can use the trusted resource environment approach.
If a data scientist is working on sensitive data of any kind, it would be wise to take legal advice, or contact the organisation’s Data Protection Officer (in the UK/EU) for guidance and to establish a governance policy and best practices documentation. This would include establishing a secure location, documenting all sources of sensitive data and all copies taken, and establish a process to scan for sensitive data. Under the GDPR, all copies of a data instance must be tracked so that the individual concerned can request complete erasure. Processes must also be established to allow employees to request access to data, and for tracking the roles of who has access at a given time.
Dealing with extremely valuable but sensitive data can be a minefield. Data scientists must be very careful not to dismiss clients’ concerns about data protection, and aim to find the appropriate middle ground between compromising privacy and compromising model performance. Often, some of the most commercially successful models are trained on highly sensitive data.
Google, Considerations for Sensitive Data within Machine Learning Datasets (2020)
Quintanilla et al, What is responsible machine learning?, Microsoft (2021)
GDPR, Right to be Forgotten, EU law (2016)
Song et al, Machine Learning Models that Remember Too Much, Cornell University (2017)
The OpenSAFELY Collaborative., Williamson, E.J., Tazare, J. et al. Comparison of methods for predicting COVID-19-related death in the general population using the OpenSAFELY platform. Diagn Progn Res 6, 6 (2022). https://doi.org/10.1186/s41512-022-00120-2
Jo Best, This open source project is using Python, SQL and Docker to understand coronavirus health data, Zdnet (2020), retrieved 6 Apri l2023
Ready to take the next step in your NLP journey? Connect with top employers seeking talent in natural language processing. Discover your dream job!
Find Your Dream Job
Fast Data Science Ltd’s flagship AI platform, the Clinical Trial Risk Tool, has been accepted as a supplier on the UK Government’s G-Cloud 15 framework.

We are pleased to announce that Thomas Wood, director of Fast Data Science, will be appearing as a panelist at the Bond Solon Expert Witness Conference on 6 November 2026 at Church House, Westminster in London. This follows Thomas’s recent appearance at the Ireland’s Expert Witness Conference on 20 May 2026.
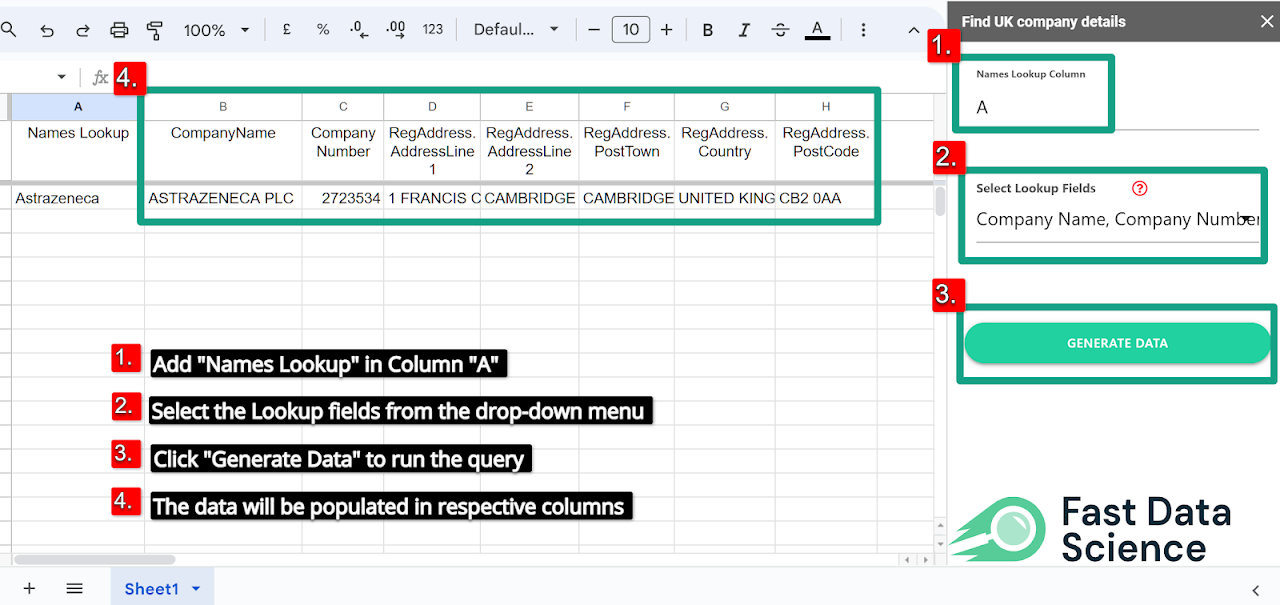
Fast Data Science are pleased to announce we have updated the UK Company Details Google Sheets™ plugin. The plugin allows you to retrieve details such as company number, incorporation date, address, and directors’ details from Companies House (the UK company registry) and automatically populate them in columns of a Google Sheets™ spreadsheet.
What we can do for you