Natural language processing (NLP) is no longer a term that makes people shake their heads and go “huh…?” – on the contrary, most businesses are aware of what it is and the powerful applications it offers through its variety of natural language APIs, text analysis APIs, and text processing APIs.
Since the rising popularity of ChatGPT and the more recent GPT-3, natural language APIs are now a very high priority for businesses of all scales and nearly across every sector. All of these NLP APIs offer promising business opportunities, and they have pretty much revolutionised how we communicate with machines and computers, enabling them to “hear”, “understand”, and “process” human language.
Similarly, NLP tools, software, and APIs have become ever more sophisticated, offering some amazing applications across multiple domains. Let’s discuss some of the best natural language processing APIs businesses should be using this year and beyond.
Today, you’ll find a number of open-source programs which can help to extract useful and insightful information from unstructured text (or any other piece of information) in order to solve business challenges, improve service delivery, optimise efficiencies, and more.
Although the list of natural language processing APIs we’ve presented in this piece is by no means comprehensive, it is still a great place to start for any business looking to capitalise on the powerful applications that NLP APIs offer. Without further ado, let’s bring you up to speed then!
Unsurprisingly, we kicked off the list with GPT-3 as it is one of the most popular and widely used natural language APIs available today. It offers a very sturdy yet ‘fashionable and trendy’ interface. Since text prediction is GPT-3’s primary use case, it can be seen as a text processing API or autocompleting application, in simple terms.
GPT-3 is known for its advanced language model and impressive text generation capabilities, allowing users to create highly coherent and contextually correct sentences. Today, it is used in various areas, including language translation, content creation, and chatbots. One major advantage it offers over other text analysis APIs is that it was pre-trained on 175 billion parameters, which means businesses can use it to produce results which are very similar to actual spoken human language.
The Google Cloud NLP API offers multiple pre-trained models for entity extraction, content categorisation, and sentiment analysis. It uses a broad range of ML and AI capabilities to comprehend dialogue and distinguish emotions as well as syntax (e.g. tokens, part-of-speech, dependence), in order to study the underlying topic and identify entities within the supplied documents.
Developers need not have extensive ML knowledge in order to use the Google natural language API to build custom ML models, as it already comes with a plethora of very powerful pre-trained models, including the AutoML Natural Language tool.
Microsoft Azure is a text analysis API which has been built using Microsoft’s robust in-house ML algorithms. This NLP API is highly useful for accomplishing four key tasks: language identification, key extraction, sentiment analysis, and named entity recognition.
One of the key advantages of this natural language processing API is that there is no need to train data or customise it to use the existing models effectively. In fact, developers can get started even if they are novice programmers. Plus, you’ll find tutorials within the NLP API which shows you how to best utilise it according to your individual programming experience.
Accessibility is very important when using a natural language API for extended durations, although it can sometimes be challenging to find the right open-source NLP technology – and even if it has the required capabilities, it may be too challenging to fully utilise from the outset.
Apache OpenNLP changes that – an open-source library for developers who value accessibility and practicality above everything else. At its core, it utilises Java NLP libraries and Python decorators.
OpenNLP is considered by many developers to be a very simple yet highly effective tool, especially when compared to leading and cutting-edge libraries like Stanford CoreNLP or NLTK, both of which offer a world of functionality (discussed later in this article). However, despite its simplicity, it offers some incredible solutions for sentence detection, tokenisation, POS tagging, and named entity recognition.
Plus, you can even customise OpenNLP according to your own needs and requirements, thus, putting unnecessary features aside which you may not need.
Natural Language Toolkit, or simply NLTK, is one of the world’s leading frameworks for developing Python programmes which, in turn, can be used to analyse human language data. According to the natural language API’s documentation, it offers wrappers for some powerful NLP libraries, a very active community, and intuitive access to over 50 corpora and lexical resources, with WordNet included.
Natural language processing
Additionally, NLTK offers a complete suite of text-processing libraries which you can use for tokenisation, tagging, parsing, stemming, categorisation, and semantic reasoning. However, it’s worth noting that learning NLTK may take time, as with most new concepts in the field of programming, although once you go through the gradual learning curve, you can write a wide variety of code to solve NLP issues.
While it may not be ideal for working with highly demanding tasks or those where huge volumes of data is involved, it contains many NLP APIs which can be used to aid in activities ranging from tagging and keyword extraction to sentiment analysis, and more.
This powerful NLP API utilises both Cython and Python. It has been developed by the same company behind NLTK, and incorporates many different word vectors and pre-trained statistical models. It also supports tokenisation for over 49 languages.
The SpaCy library is probably one of the best ones you could access, if the goal is to work with tokenisation, that is. You can break up the text into semantic units, such as punctuation, words, and articles. SpaCy offers practically all of the functionality you might need to run real-world projects, and out of all the NLP APIs currently available, it offers one of the quickest and most accurate syntactic analysis, if not the quickest or most accurate.
The Stanford NLP framework is a library for NLP activities that’s admired by developers and programmers everywhere. While the well-known SpaCy and NLTK were written in Cython and Python, CoreNLP uses Java, so you’ll need JDK installed on your machine, which contains APIs for the most popular and commonly used programming languages.
CoreNLP’s creators call it the “one-stop shop for natural language processing in Java” on their website, and we couldn’t agree more. Named entities, token and sentence borders, dependency and constituency parser, numerical and time values, quote attributions, coreference, sentiment, relations, etc. – are just some of the linguistic annotations available through CoreNLP, which currently supports six languages: Spanish, German, French, English, Arabic, and Chinese.
One very interesting thing about CoreNLP that also delights us to no end is that it is highly scalable, making it an excellent choice for complex tasks, which is an industry-leading advantage over some of the best natural language processing APIs available at the moment. The developers also built CoreNLP with speed in mind and that’s evident from the moment you start using the interface.
It’s probably fair to say that Text Blob is currently the fastest ML tool. It’s a readily accessible NLP tool developed by NLTK, offering enhanced features that provide more textual information than other NLTK-based NLP APIs.
Text Blob’s sentiment analysis, for example, can be used to contact customers via speech recognition, and you can even come up with a unique model using linguistic guidance from Big Business.
Machine translation is one of Text Blob’s most useful features, especially when standardising content has become such a high priority for developers. To further enhance your MT experience with Text Blob, we’d recommend the corpora* language text.
AllenNLP is what you’d call strong text preprocessing capabilities nicely packaged in a prototyping tool. Where SpaCy is more production-optimised compared to AllenNLP, the latter is better optimised for research purposes. Furthermore, it is powered by PyTorch, a very popular deep learning (DL) framework which offers significantly more flexibility, in terms of model customisation, than SpaCy.
PyTorch is Facebook’s own open-source ML library. This NLP API framework is excellent for content-based filtering and categorisation, as well as machine learning and computer vision, to name a few. Its library comes fully integrated with Python, which means programmers of all skills can pick it right up and start utilising it.
Additionally, PyTorch has been trained on many different kinds of models, and academics as well as researchers often use it as a natural language processing API because it is so easy to use, as well as being highly efficient and versatile.
BERT is the second Google NLP API on this list, which stands for Bidirectional Encoder Representations from Transformers. The pre-trained Google NLP API was developed to predict user intent even more accurately. Contrary to what the previous contextless approaches involved (GloVe or Word2Vec, e.g.), BERT takes into account the words which are immediately adjacent to the target word – which as you might imagine, can pretty much change how that word is interpreted.
Word2Vec is an NLP tool for word embedding where it represents a word as a vector in a high-dimensional space. By using their own dictionary definitions, words can be transformed into vectors which may then be used to train ML models in order to recognise any similarities and differences between words.
Because of its ability to capture semantic relationships with ease, Word2Vec is being used in a number of NLP tasks, including sentiment analysis, document classification, and language translation. It has proven its ability to capture word semantics and improving NLP performance as a result and should definitely be on your list of natural language processing APIs to consider in 2023.
Hugging Face offers a vast array of pre-trained NLP models and tools. It offers easy access to state-of-the-art models like RoBERTa, GPT, and Google’s NLP API, BERT. The extensive model repository and user-friendly interface make it an excellent platform for both NLP practitioners and enthusiasts.
The high-speed and scalable Python library focuses solely on topic modelling tasks, excelling at recognising similarities between texts, and navigating various documents as well as indexing texts. A major benefit of Gensim is its ability to easily handle huge volumes of data.
The Python package was developed with NLP and information retrieval in mind, with the library boasting superb processing speed, memory optimisation, and efficiency. Just make sure that you install SciPy and NumPy before installing Gensim, as the two Python packages are required for scientific computing.
MonkeyLearn is a cloud-based ML system which analysis and evaluates textual information. The text mining or text processing API is comprehensive yet straightforward, offering a myriad of pre-built text mining examples which demonstrate how best to execute tasks like topic labelling, entity extraction, sentiment analysis, and many more.
While the customisable ML models in MonkeyLearn can be modified to meet a variety of business needs, it also has the ability to connect with Google Sheets or Excel to perform in-depth text analysis.
Lexalytics is another text analysis platform similar to the cloud-based Google NLP API. It offers a number of pre-trained data and text analysis APIs which you can use quite easily, whether you have basic programming skills or even none at all.
You can also create custom solutions to suit your own applications and proficiency level. Additionally, this natural language API can be used to perform entity recognition, topic labelling, sentiment analysis, and keyword extraction, to name a few. The pre-trained models it comes with are excellent for generating data specific to your business or organisation.
BytesView is one of the best natural language processing APIs on this list and also one of the most versatile. The text analysis API offers a broad range of features, providing pre-trained models, which means even novice programmers or those with no programming experience at all can easily start using it to process and analyse massive volumes of text data. The NLP API also offers various plugins to help with the integration of data, including those used to analyse VoK queries.
Additionally, you can use this natural language API to perform anything from keyword extraction and topic labelling, to intent detection, emotion analysis and named-entity recognition, to feature extraction and semantic similarities.
The pre-trained ML models allow beginners to get started immediately while the ability to build custom models by training them through business-specific data is perfect for more experienced programmers and developers.
Scikit-learn is another very popular Python ML library which uses a variety of simple and complex text mining techniques, including clustering, regression, text classification, keyword identification, and content characterisation. It offers a simple, diverse, and connected interface, with lots of support from its dedicated community.
This open natural language API can help you take advantage of its documented functionality, so there’s no gradual learning curve just to make the most of it. In fact, Scikit-learn is one of those NLP APIs which can serve as a very valuable first lesson on text analysis. However, if you’re looking to work with more advanced DL techniques, then it probably shouldn’t be your first choice.
TensorFlow is a Google NLP API supporting multiple languages and an open-source library. It is typically used for deep learning as well as advanced text categorisation, tagging, summarisation, and speech recognition. Large enterprises have been using this text processing API to construct deep learning models for analysing their business data on a large scale.
TensorFlow’s NLP APIs come in many different programming languages as well, with Python being the most commonly used as it is, unsurprisingly, the most user-friendly. However, the natural language API does require a steep learning curve, so it is probably not idea for novice programmers.
This natural language processing API offers a wide range of AI-based services, all housed in the IBM cloud. It offers a versatile suite of tools which can help you perform multiple natural language understanding (NLU) tasks like identifying emotions, keywords, and categories.
Thanks to its excellent flexibility and versatility, IBM Watson is currently being used in many different industries, including healthcare, banking, and finance.
CogCompNLP is considered the “Swiss army knife” of natural language processing API by many amateur and experienced developers alike. It simplifies the entire process involved in the design and development of NLP APIs by providing unique modules to address a variety of challenges – including a dedicated module for corpora support, one for multiple low-level data structures and operations, and another one for feature extraction, for instance.
Furthermore, CogCompNLP is available in both Java and Python for processing text data, allowing you to store everything either remotely or locally. Other common features include part-of-speech tagging, lemmatisation, tokenisation, semantic role labelling, etc.
Transformers is one of the most powerful and best natural language processing APIs you can try today, offering a robust NLP library which encompasses multiple transformer-based models such as T5, GPT, and BERT.
The unified interface is ideal for training and deploying transformer models across multiple tasks, including question-answering, text generation, and text classification. Transformers has gained massive popularity over the years, thanks to its unsurpassed performance and versatility.
NLP has emerged as a technology in recent years which businesses simply can’t do without. It has revolutionised the way we interact with machines and computers, enabling them to quickly understand and process human language.
With more advancements in the works in ML, AI, and NLP, powerful NLP APIs have emerged to offer various applications across multiple sectors, helping businesses become more productive and competitive.
However, with so many options available in the current market, choosing the right natural language processing API can be difficult. After all, how do you know for sure if it will meet all business requirements? Be user-friendly enough for everyone in your team to pick up and use? Be versatile and flexible enough to apply across multiple use cases?
While this article certainly makes it easier to understand where to start by discussing the best natural language processing API you can try right now, it also pays to understand which NLP APIs can specifically benefit your business. We’ve certainly handpicked some top-notch examples, which you might benefit from to break down complex data in order to gain actionable insights.
Both text analysis APIs and text processing APIs which are ready-made and available to everyone is a good way to start out with text mining and other data analysis-related tasks. It allows you to harness the power of a well-honed NLP API which can be used across a wide range of applications and is relatively free of bugs, allowing you both SaaS and open-source natural language processing APIs to choose from.
At Fast Data Science, we not only help businesses make the most of the available natural language APIs but also build custom NLP APIs to really help you get into the depth of your unstructured data.
Textual data is a very powerful tool that you can use today to improve employee efficiency, customer experience satisfaction, and other areas of the business. We can help you choose the perfect natural language processing API after assessing your project size, budget, and technological capabilities.
We offer a comprehensive, robust, and easy-to-use solution which is also budget-friendly and customised to help you gain the most insights from unstructured data.
To learn more, consult one of our expert data scientists now.
Tags
Google NLP API, natural language processing API, NLP APIS, Google natural language API, natural language API, best natural language processing API, text analysis API, text processing API
Unleash the potential of your NLP projects with the right talent. Post your job with us and attract candidates who are as passionate about natural language processing.
Hire NLP Experts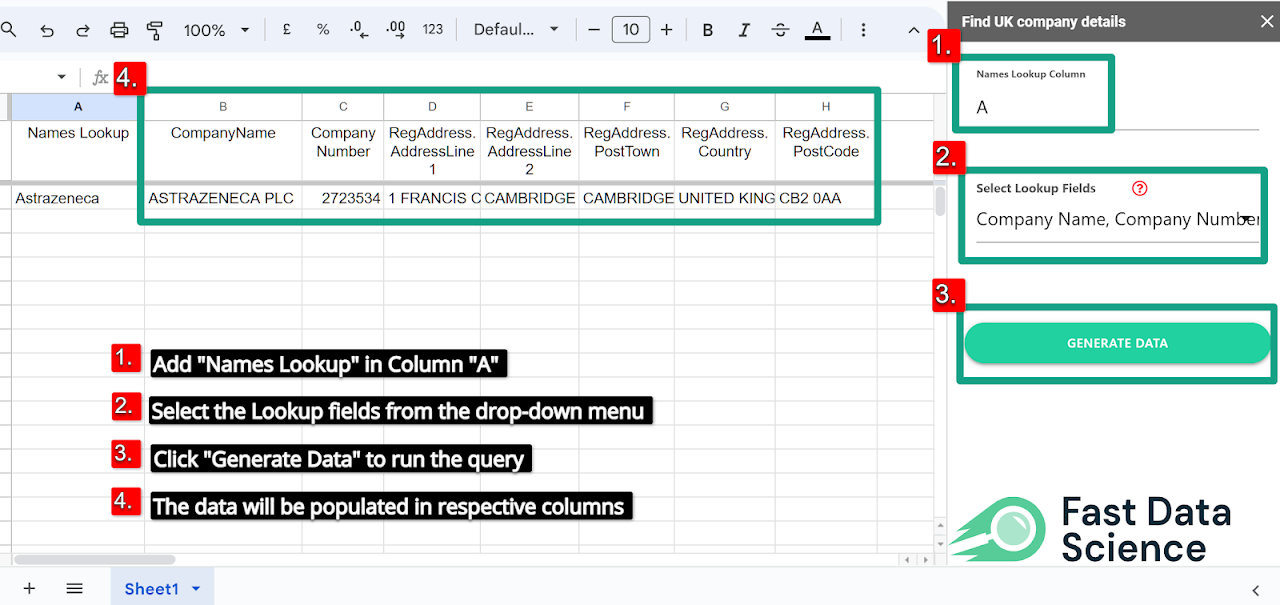
Fast Data Science are pleased to announce we have updated the UK Company Details Google Sheets™ plugin. The plugin allows you to retrieve details such as company number, incorporation date, address, and directors’ details from Companies House (the UK company registry) and automatically populate them in columns of a Google Sheets™ spreadsheet.

This is an article based on my presentation on “The Role of Artificial Intelligence in Expert Investigations and the Preparation of reports” which I gave at the Expert Witness Conference on 20 May 2026.

Many companies and organisations have large datasets that are stored in a very unstructured format. For example, you could work for a US based healthcare provider or insurer and have patient records stored in a free text format such as HL7 files or PDFs. A building regulator, land registry, or mortgage provider may have texts and accompanying diagrams from thousands of building inspections or land title deeds. A patent attorney’s office may have records of patent applications in PDF format.
What we can do for you