
What is sentiment analysis and what are the key trends in sentiment analysis today? Understand and try out some of the simplest and most cutting-edge sentiment analysis technologies!
My first encounter with natural language processing as a field was in 2007 when I began studying a Masters after completing my undergraduate degree in Physics. At that time, the technology in use for language processing was very different from today’s cutting-edge approaches.

The development of sentiment analysis techniques
Imagine that your task is to identify whether a film or product review indicates positive or negative sentiment on the part of the writer. The simplest possible approach to do this is to compile a list of positive and negative words and and simply count the positive and negative words in the sentence.
This is how the earliest sentiment analysis algorithms worked and it’s called the lexicon-based approach. For example, the AFINN sentiment score list, developed by Finn Årup Nielsen in 2011, contains a list of words in the English language with a score assigned to each one between -5 and +5. Here is an excerpt of the AFINN lexicon:
friendly 2
frightened -2
frikin -2
frustration -2
ftw 3
...
positive 2
positively 2
postpone -1
postponed -1
postpones -1
postponing -1
poverty -1
praise 3
praised 3
The sentiment score for a movie review such as “This movie was absolutely awful” can be calculated by simply summing the the polarities of the words in the sentence. Although this simple approach has its advantages, it’s quite easy to break it.
For example, sentences containing negative words or sarcasm simply cannot be handled by a lexicon. And what about “This movie was positively awful” (you can see that positively scores +2 in AFINN no matter the context).
Too much information is lost when we take only the words in the sentence and ignore their context.
(Keep reading to try a demo of the AFINN sentiment analysis algorithm in Javascript, and compare it with a more state-of-the art option.)
When I was doing my Masters, I remember studying at variety of increasingly complex handcrafted rules whereby engineers tried to codify the grammar of the English language in order to solve this problem. For example, the polarity score of a word was affected if it occurred within a narrow window of a negation word such as “not”.
An example of this approach is the VADER library, which stands for Valence Aware Dictionary and sEntiment Reasoner. This has a set of rules for negation, for all-caps (intensification of feeling), and also a list of special cases such as “to die for”.
 console using VADER.](https://raw.githubusercontent.com/fastdatascience/.github/master/profile/fast_data_science_nlp_sentiment_analysis_demo.png)
A demonstration of some simple sentiment analysis in the Python console using VADER.
A library such as VADER can do the trick if you need a simple lightweight solution.
Over the next decade, the NLP community shifted away from manually coded rules towards a machine learning approach. The earliest machine learning sentiment analysis algorithms used a hybrid of hand-coded features and weights. For example, an engineer could write code to extract a number of features (is the word “not” within a window of 5 tokens?), and a machine learning algorithm such as logistic regression can learn how important a feature is.
In 2013, a team of researchers at Google led by Tomáš Mikolov developed the word vector embedding approach with the Word2vec algorithm, and word vector embeddings such as Word2vec and GloVe became the new gold standard for a number of NLP problems, including text classification and sentiment analysis.
Word embeddings work by signing a single vector in Cartesian space to every word in the lexicon. Words which are similar in meaning or function are close to each other in the vector space, whereas words which are very different will be located far apart. Using the word embeddings approach, a sentence can be converted from plain text into a matrix of numbers not unlike an image, and then can be passed into either a convolutional neural network or another deep neural network architecture such as an RNN or LSTM.
The Word2vec approach combined with a neural network allows a machine learning model to pick up clues from the context of a sentence, and so word vector based models are not as vulnerable to nuances of meaning and navigation as as their predecessors.
The current state of the art in sentiment analysis is the transformer approach. The best-known transformer model is called BERT. Transformers work in a similar way to word vector embeddings, in that words in a sentence are transformed into vectors in a huge multidimensional space. However, one difference is that a transformer model can represent a word as a different vector depending on its function in a sentence.
Unfortunately, the most sophisticated deep learning models such as transformers require a lot of training data and are very power hungry, so in practice they are not always used. It is often impractical for a researcher or NLP engineer to run or train a transformer model on their own computer, and so the only practical way is to use a cloud-based service or cloud-based sentiment APIs such as those provided by Google, Microsoft, or Amazon.
Cloud-based sentiment analysis may not always be an option in industry as many clients have confidential data, such as healthcare data, which cannot be allowed to leave the premises.
Below you can try out the first approach I mentioned in this article, to see its limitations for different kinds of complex sentences. Is it easier to fool the lexicon-based sentiment analyser than a cloud-based or LLM sentiment analyser? How well do they handle sarcasm?
If you are limited by confidentiality or other commercial factors and are unable to use a cloud-based sentiment analysis service, then the library that I would recommend to use on your own computer would be the NLTK or spaCy libraries in Python, or their equivalents in R. These models can run out of the box and sometimes are quite straightforward to train. If your computer is powerful enough you could try a transformer model such as BERT - there are some useful tutorials on the website HuggingFace.
One of the best-known ways of measuring the performance of sentiment analysis algorithms is the IMDb dataset - this is a collection of 50,000 movie reviews from the IMDB movie database. Reviews are categorised as positive or negative, and a machine learning algorithm must classify these correctly.
One of the other reviewers has mentioned that after watching just 1 Oz episode you’ll be hooked.
(sample positive review from IMDb dataset)
Since 2011, when bag-of-words algorithms were able to categorise 88% of the reviews accurately, transformer models have pushed this frontier to an amazing 96%.
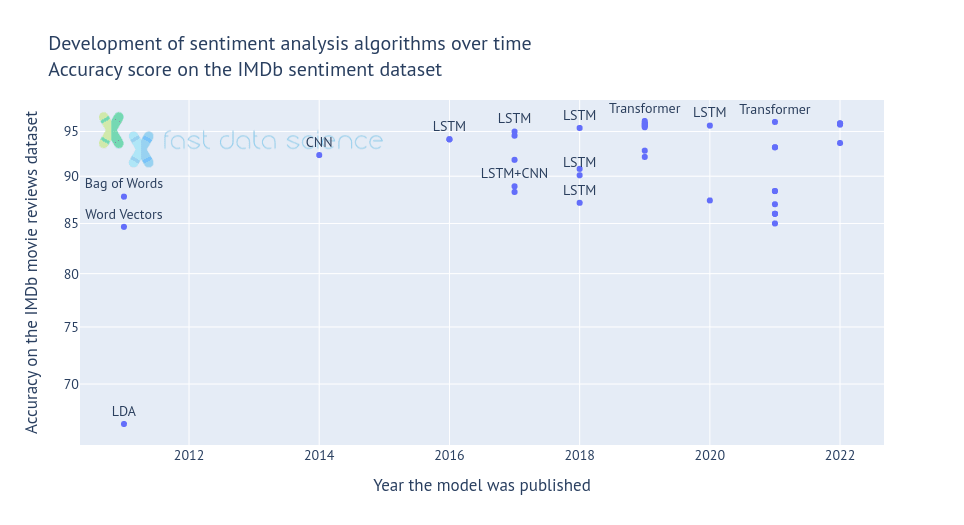
Performance of a selection of NLP sentiment analysis models on the IMDb benchmark, showing an improvement from 88% (Maas et al, 2011) to 96% in recent years.
What are the commonest uses of sentiment analysis in industry is for monitoring opinions of the general public about products, services and businesses. Many dissatisfied customers will not communicate their negative feedback directly, and so sentiment analysis software allows organisations to detect changes in public opinion or customer dissatisfaction. There are a number of off-the-shelf social media monitoring platforms which allow marketing managers to monitor sentiment in real time.
With the proliferation of chatbots on corporate websites, sentiment analysis can be useful to triage the most dissatisfied customers to a human customer service representative instead of a bot. Sentiment analysis is able to pick up customer tone and handle an unhappy customer accordingly.
Pharmaceutical companies are increasingly facing the challenge of monitoring the usage and efficacy of their products once they are already on the market. This contrasts with the large amount of information available to pharmaceutical companies before a drug is put on the market due to the rigorous clinical trials process.
Many of these companies receive large amounts of telephone transcripts or survey responses from healthcare practitioners or other customers around the world. Sentiment analysis software which has been specialised for the pharmaceutical domain allows a pharma company’s aftermarket representative to identify key trends such as X% of doctors interviewed would not give two particular drugs in combination to a patient with a particular heart condition because they have observed negative side effects in similar cases in the past.
Traditional market research surveys were often entirely quantitative and relied on the standardised Likert scale. Respondents were asked to rate statements or products on a 5-point scale from 1 (strongly disagree, like it very much) to 5 (strongly agree, dislike it very much). However, with the advent of natural language processing, market researchers now have the option to use free text fields in their surveys and categorise responses using natural language processing techniques such as sentiment analysis, topic modelling, document classification, and word clouds.
In the time I have been working in natural language processing, I have seen many changes in techniques and the philosophy of the field has gone from almost entirely lexical and rule-based approaches to the opposite extreme of machine learning models with no manually engineered features at all. The performance of sentiment analysis algorithms has improved drastically. However, the simplest models are sometimes the best. When you have a very small amount of training data, even a lexicon-based approach can deliver value.
Of course, the customer’s needs come first and and I would develop any sentiment analysis application based on on what performs the best, which is not necessarily a neural network. On some of my NLP projects, only 10 or 20 training documents may be available. This could be due to client confidentiality concerns, or simply the difficulty of tagging or obtaining large amounts of data. In cases where there is not much data, the natural language processing engineer must be creative. Often, that involves the use of older or simpler technologies rather than the latest groundbreaking models.
Unleash the potential of your NLP projects with the right talent. Post your job with us and attract candidates who are as passionate about natural language processing.
Hire NLP Experts
Fast Data Science Ltd’s flagship AI platform, the Clinical Trial Risk Tool, has been accepted as a supplier on the UK Government’s G-Cloud 15 framework.

We are pleased to announce that Thomas Wood, director of Fast Data Science, will be appearing as a panelist at the Bond Solon Expert Witness Conference on 6 November 2026 at Church House, Westminster in London. This follows Thomas’s recent appearance at the Ireland’s Expert Witness Conference on 20 May 2026.
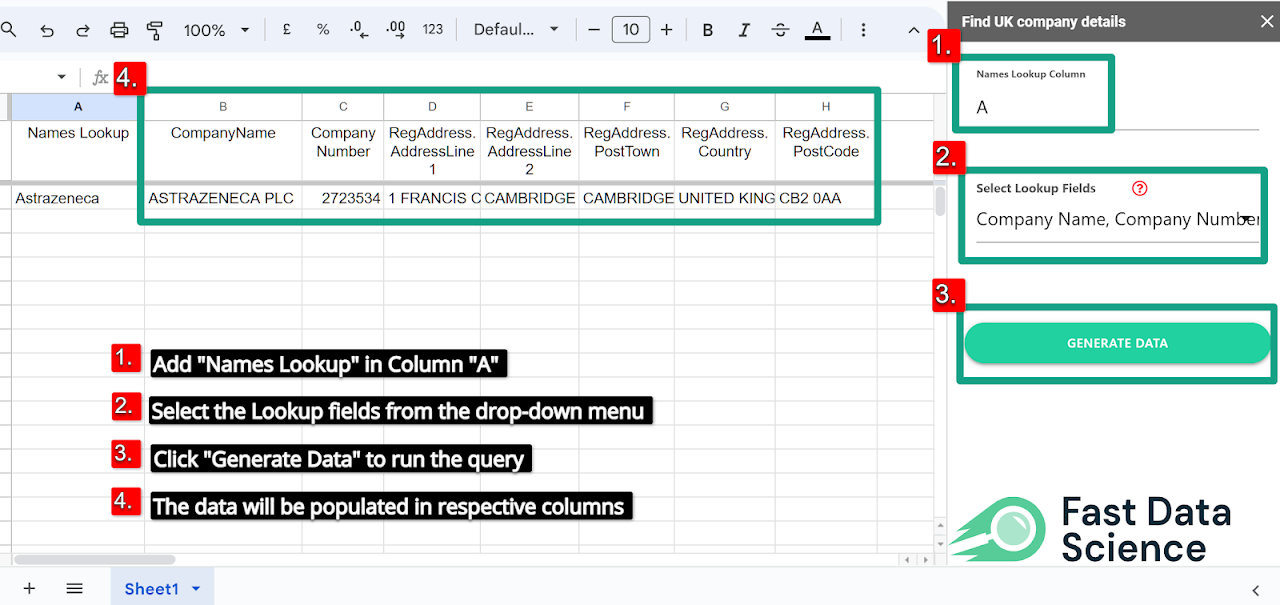
Fast Data Science are pleased to announce we have updated the UK Company Details Google Sheets™ plugin. The plugin allows you to retrieve details such as company number, incorporation date, address, and directors’ details from Companies House (the UK company registry) and automatically populate them in columns of a Google Sheets™ spreadsheet.
What we can do for you