
Natural Language Processing (NLP) is an area of AI. It is the science of getting computers to interact with humans in our languages - in other words, getting computers to speak, understand, and generally produce human language.
NLP could involve text, audio files, or any kind of documents. You will interact with an NLP system if you use ChatGPT or Gemini, for example. Businesses often have a need for natural language processing, if they have large amounts of unstructured text data. Typical examples of this include medical reports, legal cases, insurance claims, building, vehicle, or ship inspection reports, or scientific literature.
At Fast Data Science we take on a lot of consulting work around natural language processing in industries where a lot of text is generated, such as legal, healthcare and pharma.
Well-known uses of natural language processing include:
Natural language processing has been around for years but is often taken for granted. Here are some example applications of natural language processing which you may not know about. If you have a large amount of text data, you can consider hiring an external NLP consultant such as Fast Data Science.
Here’s an overview of some business uses of NLP:
When companies have large amounts of text documents (imagine a law firm’s case load, or regulatory documents in a pharma company), it can be tricky to get insights out of it.
For example, a pharmaceutical executive may want to know of the thousands of clinical trials that the firm has run, how many resulted in a particular side effect, when that information is stored in a stack of documents (or medical notes in a plain text format), rather than a database, and nobody has time to read all the documents.

If the data had been entered into a database and coded in a very rigid way, with dropdowns and fixed options, then Traditional Business Intelligence (BI) tools such as Power BI and Tableau would allow analysts to get insights out of the structured database. Standard business intelligence tools let analysts see at a glance which team made the most sales in a given quarter, for example.
But a lot of the data floating around companies is in an unstructured format such as PDF documents, and this is where Power BI cannot help so easily, and natural language processing can help identify patterns in unstructured data.
For example, topic modelling (clustering) can be used to find key themes in a document set, and named entity recognition could identify product names, personal names, or key places. Document classification can be used to automatically triage documents into categories.
At Fast Data Science, we have developed systems to combine text data with other business information such as project success and risk. The Clinical Trial Risk Tool allows a user to drag and drop a PDF of a clinical trial protocol and it will generate a benchmark cost, risk score, and budget, by pulling information out of the PDF.
The best way to analyse a large set of uncategorised text responses is to use a topic modelling algorithm such as k-means or Latent Dirichlet Allocation. For example, if you have 10,000 customer satisfaction forms where customers have submitted a description of why they are cancelling their contract, it can be hard to find and categorise their reasons and look for patterns, as there is simply so much text and nobody has time to read all the responses.
A topic modelling algorithm lets you specify that you want the top six topics mentioned in your responses, and it will find the topics and identify which texts belong to which topic. This lets you do things like create a pie chart of “top six reasons for cancelling contracts”, and even segment by demographic (e.g. the over-65s were 20% more likely to cancel a contract due to lack of cash payments than other age groups).
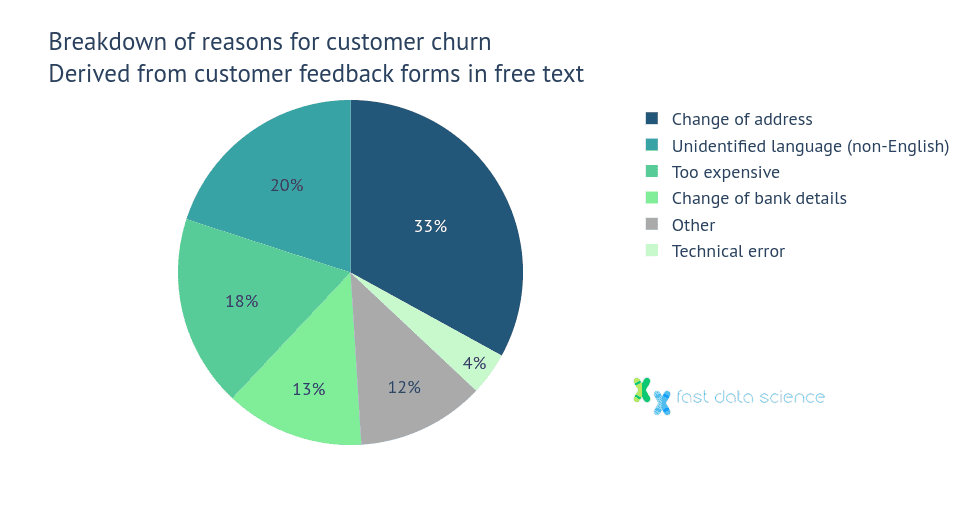
Above: if you had 10,000 responses to a customer satisfaction survey, you can run a clustering or topic modelling algorithm and produce simple breakdowns like the pie chart above.
Fast Data Science ran a full analysis of a market research project for an American financial institution and we have shared how we did it in this blog post.
There are very useful open source tools such as Apache Tika, which is able to convert PDF documents into plain text. You can then train and run natural language processing models on the plain text.
If there is information in tabular form in the documents, you can use libraries like PdfPlumber to pull out the table structure from the PDFs.
After the PDF-to-text conversion, the text is often messy, with page numbers and headers mixed into the document, and formatting information lost.
You can then use the appropriate machine learning model to pull out the information that you need. For example, if you need to pick up the ICD-O coding for cancer types diagnosed and suspected, then you might run a medical named entity recognition component which looks for any cancers mentioned by name, and then combine that with a machine learning model or large language model to identify if a particular mention of a cancer type was confirmed diagnosed or just suspected, whether it is primary or secondary, and where in the body it occurred.
One of the simplest types of NLP is to categorise documents into a small number of classes. This generally doesn’t need a large language model, and can be done with an algorithm like Naive Bayes. You just need to manually tag a decent number of documents in each class - let’s say 50 of each category - and then train your model. The model can learn the words and patterns that correlate with a document being in each category.
For example, the machine learning model will learn that “interest” correlates with the “finance” category while “dosage” is correlated with the “pharma” category. These words are not absolutes - they have weights, and some are stronger indications of a category than other. Words like “the” are called stopwords and are normally excluded.
Here you can try out a very simple two-class Naive Bayes classifier:
Classifies text as "HIV" or "TB" and highlights word contributions. This classifier was trained in Python on 39 labelled clinical trial protocols in both of these classes.
The Naive Bayes classifier has shaded words in green if they favour the HIV class. Words shaded red favour the TB class.
If documents need to be classified and integrated with a legacy system, the easiest solution is to train a machine learning model and deploy it as an API to a cloud or on-premises hosted provider. If HIPAA compliance is an issue, the model must be set up to avoid logging and caching of inputs, and use a completely secured connection. Once your API is set up, your legacy system can be made to point to it and send a request perhaps with a batch of documents, asking the system to categorise them. The system should return a confidence score. Naive Bayes models are easier to work with than large language models, but it’s possible to deploy large language models to the cloud and remain HIPAA or GDPR compliant.
Fast Data Science can deploy the model for you and assist with integrating it into your legacy systems.
Above: a video walkthrough of some examples of NLP and how it can be used in business.
There has recently been a lot of hype about large language models and generative AI. Large language models rely on a design called the transformer architecture. Transformers can represent the grammar of natural language in an extremely deep and sophisticated way and have vastly improved the performance of search engines, document classification, text generation and question answering systems.
The easiest way to get started with transformer models like BERT is to install a library called Hugging Face. Below you can see my experiment retrieving the facts of the Donoghue v Stevenson (“snail in a bottle”) case, which was a landmark decision in English tort law which laid the foundation for the modern doctrine of negligence. You can see that BERT was quite easily able to retrieve the facts (On August 26th, 1928, the Appellant drank a bottle of ginger beer, manufactured by the Respondent…). Although impressive, at present the sophistication of BERT is limited to finding the relevant passage of text.
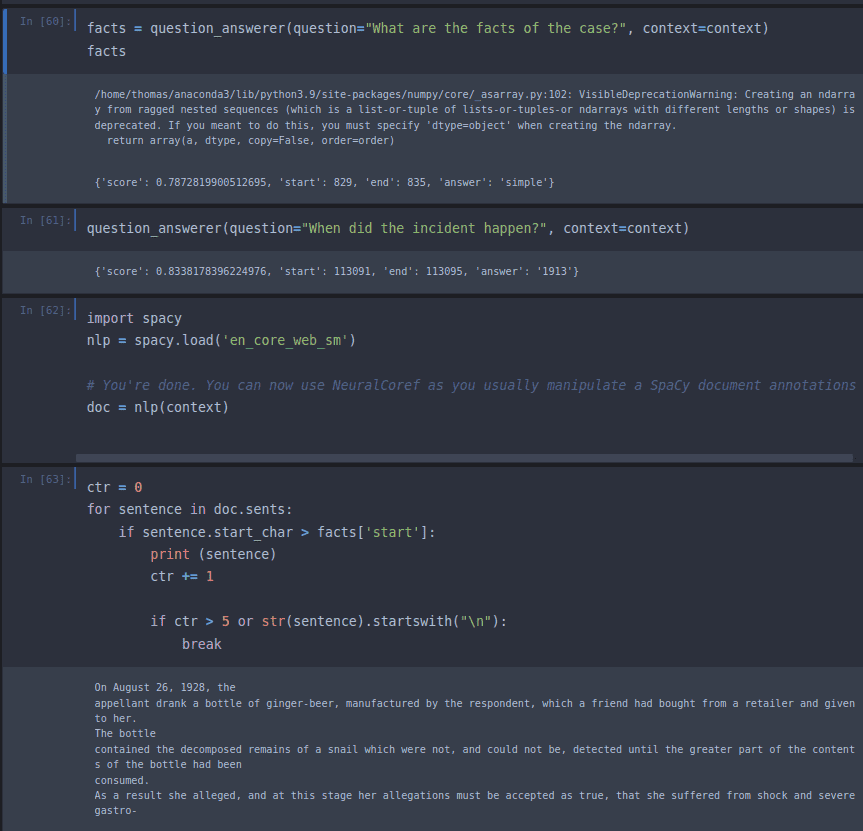
The OpenAI API lets you also retrieve information in a structured format such as JSON or CSV, meaning that you could feed it a PDF of a legal case and ask it to populate a table of appelants and defendants.
There are a number of use cases which Fast Data Science has worked on where there was a requirement to turn very unstructured text into a structured format, such as:
The simplest way to approach this kind of problem is to combine rule based systems with large language models such as the OpenAI API, perhaps over the Azure or AWS platform.
You can develop a deployed API, which receives the input text and outputs an Excel or other structured format for your systems, with options for the user to refine their prompt.
You can use rule based systems to identify any entities mentioned, and if constraints allow, you could combine the rule-based system with a structured output formats such as OpenAI’s JSON format.
Quite often, we have had requirements to reconcile disparate systems, such as an accounting system, tax payers system, and publications list or conference attendees list. This is an inexact problem and very tricky to do by hand once you have thousands of people to reconcile, but there are many NLP tools that can help.
Matching and disambiguating named persons with a fuzzy matching process is an inexact task but this has come up quite frequently in our consulting engagements. We have had several clients in the past with analogous requirements to link personal details from multiple systems.
For example, we had to build a database of counsellors and psychologists in the UK, combining data from one source that verifies their qualifications, with other sources that contain contact details and hourly rates. We’ve often done this kind of project around academic publications and authorship, since the way authors of publications are cited can be ambiguous (married names, maiden names, German names containing äöü, and Chinese names have been particularly challenging).
Our general approach is to identity a number of features that could indicate a match, and train a machine learning model to determine the probability of two people being the same person given what we know about them. This allows us to triage name pairs into those which are definite matches, those which are definite non matches, and those which need manual verification.
We would take the following steps:
We would ensure that the matching algorithm accounts for variations in the data, such as typos, abbreviations, and synonyms, as well as idiosyncrasies such as accented characters and maiden names. We would manually check matches that fall below the confidence threshold and decide whether they should be accepted or rejected as a match.
One problem I encounter again and again is running natural language processing algorithms on documents corpora or lists of survey responses which are a mixture of American and British spelling, or full of common spelling mistakes. One of the annoying consequences of not normalising spelling is that words like normalising/normalizing do not tend to be picked up as high frequency words if they are split between variants. For that reason we often have to use spelling and grammar normalisation tools.
After this problem appeared in so many of my projects, I wrote my own Python package called localspelling which allows a user to convert all text in a document to British or American, or to detect which variant is used in the document.
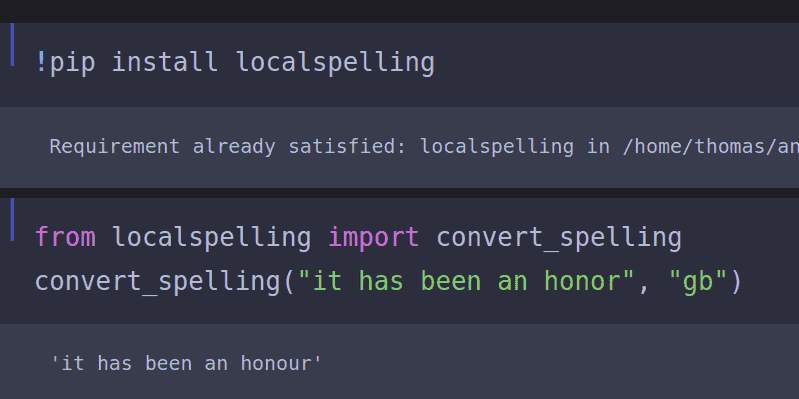
Although spelling normalisation may seem unimportant, the BBC reported in 2022 that spelling mistakes are costing the UK millions of pounds in lost revenue, and that a single spelling mistake on a website can half a conversion rate. Unbeleivable!
Given a text in an unknown language, it’s surprisingly easy for natural language processing to identify the language. There are two main approaches to language identification:
Language identification through stopword lists
An NLP system can look for stopwords (small function words such as the, at, in) in a text, and compare with a list of known stopwords for many languages. The language with the most stopwords in the unknown text is identified as the language. So a document with many occurrences of le and la is likely to be French, for example.
Language identification from N-gram lists
A slightly more sophisticated technique for language identification is to assemble a list of N-grams, which are sequences of characters which have a characteristic frequency in each language. For example, the combination ch is common in English, Dutch, Spanish, German, French, and other languages.
But the combination sch is common only in German and Dutch, and eau is common as a three-letter sequence in French. Likewise, while East Asian scripts may look similar to the untrained eye, the commonest character in Japanese is の and the commonest character in Chinese is 的, both corresponding to the English ’s suffix.
By counting the one-, two- and three-letter sequences in a text (unigrams, bigrams and trigrams), a language can be identified from a short sequence of a few sentences only.
The below demo of a language detector uses the “Efficient Language Detector” library available at: https://github.com/nitotm/efficient-language-detector-js
Enter text below and click "Detect Language" to see the results from the `eld` library.
As an extension of the above problem, sometimes a text appears with an unknown author and we want to know who wrote it.
Examples include novels written under a pseudonym, such as JK Rowling’s detective series written under the pen-name Robert Galbraith, or the pseudonymous Italian author Elena Ferrante. In politics we have the anonymous New York Times op-ed I Am Part of the Resistance Inside the Trump Administration, which sparked a witch-hunt for its author, and the open question about who penned Dominic Cummings’ rose garden statement.
The excellent linguistics YouTuber Joshua R has walked through a qualitative analysis of a French message written by one of the Bataclan terrorists in 2015, where he has identified key demographic information behind the author (education level, cultural upbringing, etc).
The science of identifying authorship from unknown texts is called forensic stylometry. Every author has a characteristic fingerprint of their writing style - even if we are talking about word-processed documents and handwriting is not available.
You can read more about forensic stylometry in my earlier blog post on the topic, and you can also try out a live demo of an author identification system on the site.
Although forensic stylometry can be viewed as a qualitative discipline and is used by academics in the humanities for problems such as unknown Latin or Greek texts, it is also an interesting example application of natural language processing.
We are past the days when machine translation systems were notorious for turning text such as “The spirit is willing but the flesh is weak” into “The vodka is good but the meat is rotten.” (Although the Economist reliably informs me that this story is apocryphal.)
Today, Google Translate covers an astonishing array of languages and handles most of them with statistical models trained on enormous corpora of text which may not even be available in the language pair. Transformer models have allowed tech giants to develop translation systems trained solely on monolingual text.
In 2022, Meta announced the creation of a single AI model capable of translating across 200 different languages, democratising the access to natural language processing to lesser spoken languages such as Twi (Ghana) which were previously not supported by NLP tools.
The monolingual based approach is also far more scalable, as Facebook’s models are able to translate from Thai to Lao or Nepali to Assamese as easily as they would translate between those languages and English. As the number of supported languages increases, the number of language pairs would become unmanageable if each language pair had to be developed and maintained. Earlier iterations of machine translation models tended to underperform when not translating to or from English.
However, there is still a lot of work to be done to improve the coverage of the world’s languages. Facebook estimates that more than 20% of the world’s population is still not currently covered by commercial translation technology. In general coverage is very good for major world languages, with some outliers (notably Yue and Wu Chinese, sometimes known as Cantonese and Shanghainese).
Top 91 languages showing Google Translate coverage. Data source: Ethnologue (2022, 25th edition), Google Translate homepage.
Many of the unsupported languages are languages with many speakers but non-official status, such as the many spoken varieties of Arabic.
Interestingly, the Bible has been translated into more than 6,000 languages and is often the first book published in a new language.
Sentiment analysis is an example of how natural language processing can be used to identify the subjective content of a text. This is naturally very useful for companies that want to monitor social media traffic regarding their brands and competitor brands or key topics, and also to monitor the sentiment of dialogue between users and chatbots or customer support agents. Sentiment analysis has been used in finance to identify emerging trends which can indicate profitable trades.
For more examples of how this area of natural language processing can be applied in your business please check out my blog post on trends in sentiment analysis which includes an interactive demo of a sentiment analysis tool and shows how sentiment analysis technology has progressed from the 1970s up to today.
Spelling and grammar checkers are now commonplace and we often overlook them.
You would think that writing a spellchecker is as simple as assembling a list of all allowed words in a language, but the problem is far more complex than that. How can such a system distinguish between their, there and they’re , or program vs programme? Nowadays the more sophisticated spellcheckers use neural networks to check that the correct homonym is used. Also, for languages with more complicated morphologies than English, spellchecking can become very computationally intensive.
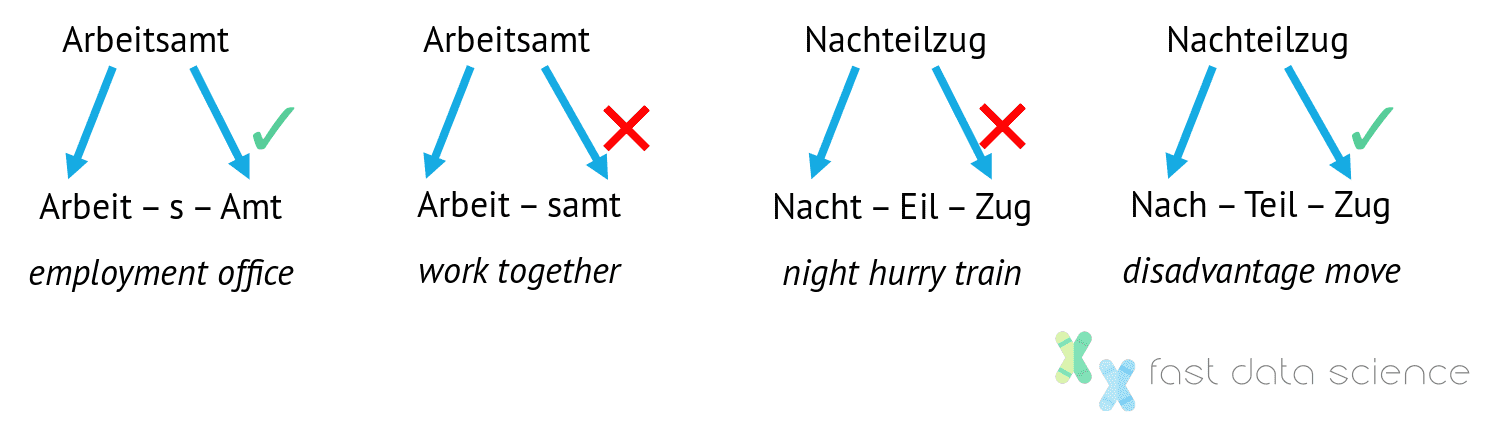
As an example of a non-English-specific problem in natural language processing, a German spellchecker must deal with the problem of Kompositazerlegung: splitting compound words into their constituent parts. Sometimes there is more than one valid splitting, although only one makes sense to a human reader. Open-source software such as LibreOffice can perform this task using the library Hunspell, which was first developed for Hungarian, a language with a very complex morphology.
Natural language processing can rapidly transform a business. Businesses in industries such as pharmaceuticals, legal, insurance, and scientific research can leverage the huge amounts of data which they have siloed, in order to overtake the competition.
Natural language processing can be used to improve customer experience in the form of chatbots and systems for triaging incoming sales enquiries and customer support requests.
For further examples of how natural language processing can be used to your organisation’s efficiency and profitability please don’t hesitate to contact Fast Data Science.
Yes, we often have projects involving documents in very messy formats, such as scanned PDFs. We find that tools like Apache Tika are excellent for pulling structured data out of PDFs.
SIL International, Ethnologue: Languages of the World (2022, 25th edition)
The Economist, A Gift of Tongues (2009)
NLLB Team, Scaling neural machine translation to 200 languages, Nature 630.8018 (2024): 841.
Ready to take the next step in your NLP journey? Connect with top employers seeking talent in natural language processing. Discover your dream job!
Find Your Dream Job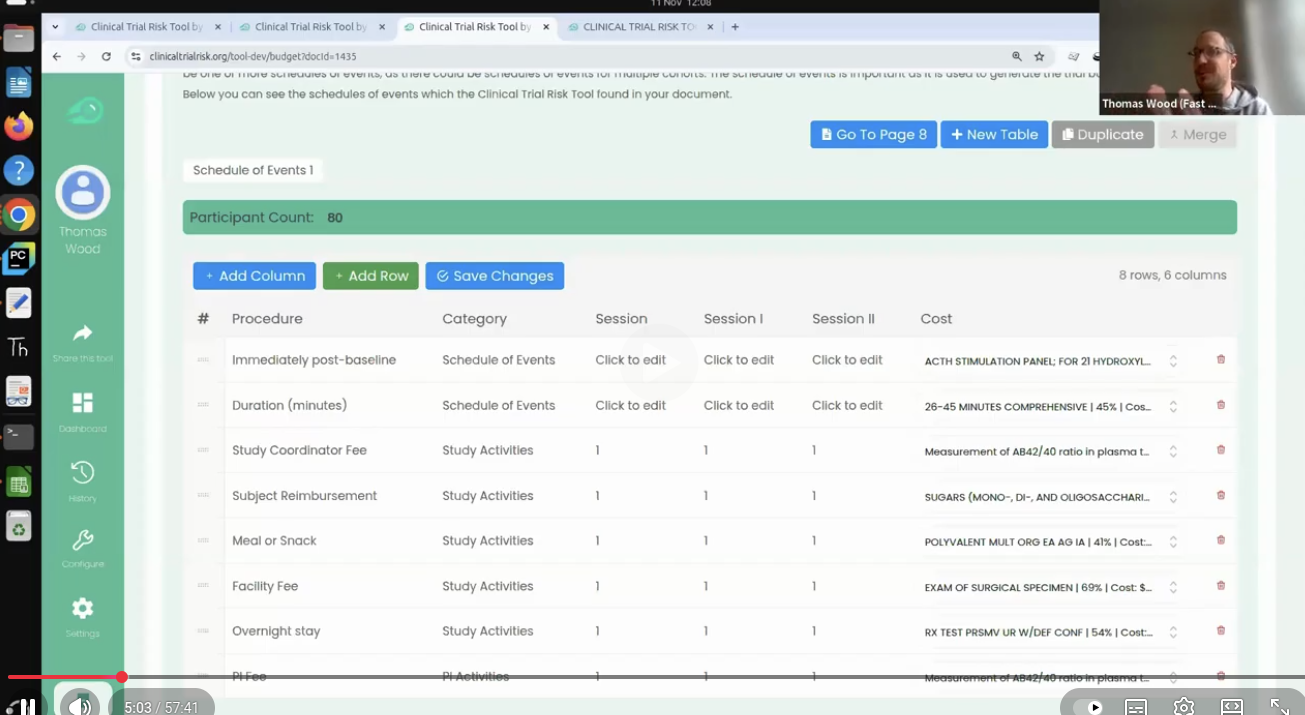
Fast Data Science Ltd’s flagship AI platform, the Clinical Trial Risk Tool, has been accepted as a supplier on the UK Government’s G-Cloud 15 framework.

We are pleased to announce that Thomas Wood, director of Fast Data Science, will be appearing as a panelist at the Bond Solon Expert Witness Conference on 6 November 2026 at Church House, Westminster in London. This follows Thomas’s recent appearance at the Ireland’s Expert Witness Conference on 20 May 2026.
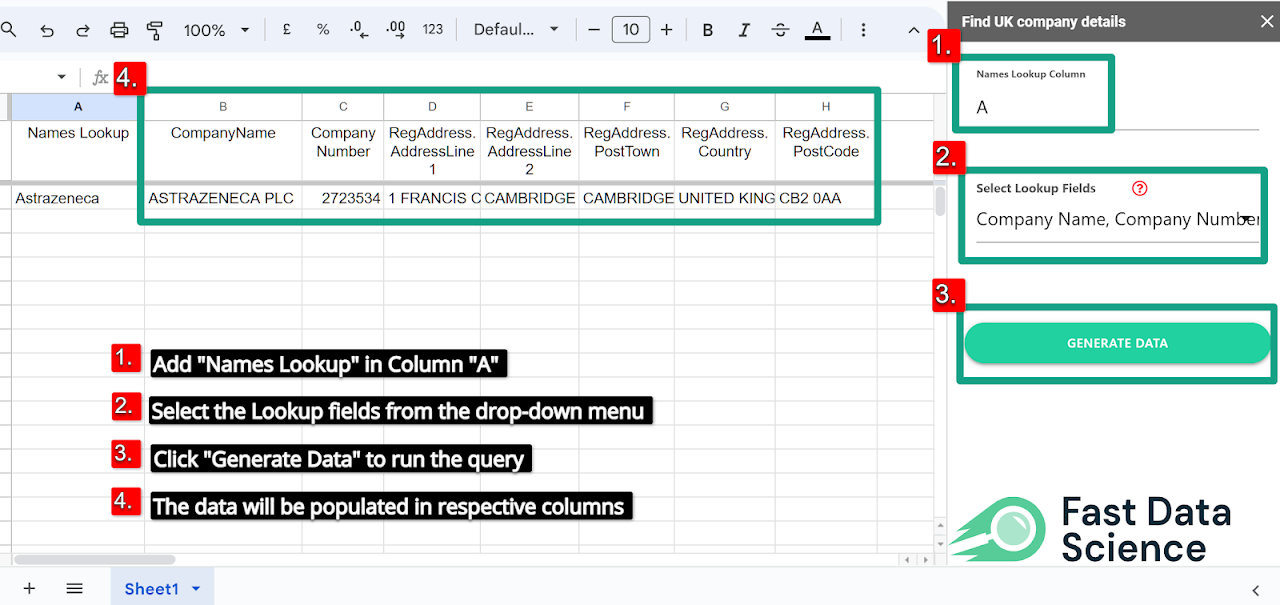
Fast Data Science are pleased to announce we have updated the UK Company Details Google Sheets™ plugin. The plugin allows you to retrieve details such as company number, incorporation date, address, and directors’ details from Companies House (the UK company registry) and automatically populate them in columns of a Google Sheets™ spreadsheet.
What we can do for you
{kind=link}