
People often ask us, what kind of consulting do we do at Fast Data Science? If we say NLP, the next question is normally, ‘what is NLP?’, and we need to explain a bit further what NLP stands for and what it means.
NLP stands for Natural Language Processing… but after 12 years in the field, Google hasn’t learnt from my search history. Screenshot from Google.
The short answer is: NLP stands for Natural Language Processing. The “Natural” in Natural Language Processing refers to human languages, such as English, as opposed to programming languages. “Processing” refers to what we do with it: we try to get computers to understand human languages. In short, NLP means computer programs that either understand or generate speech or text. NLP is a sub-field of artificial intelligence, and regularly makes use of machine learning techniques.
Here are a few commonplace applications of NLP in our ordinary lives:
Predictive text is an NLP model which is able to predict the most likely next word in your sentence. It is a ’language model’ which combines a general English language model trained on many users’ texting histories, together with personalised patterns that is has learnt from your own typing history on your phone.
For East Asian languages such as Chinese, NLP algorithms such as predictive text are essential for effective use of a mobile phone. In one of the commonest input methods used in China, a user types words in pinyin (the phonetic representation), and the language model is able to choose the most likely character for that pronunciation given the context of the rest of the sentence.
Demonstration of the standard predictive text algorithm in English and Chinese on the Samsung Galaxy S7.
Spellcheckers are applications that test spelling and grammar, finding orthographical, stylistic, and grammatical errors and providing helpful suggestions on how to fix them. For example, I wrote this article with the help of the browser plug-in Grammarly, which uses NLP to improve your writing style.
Screenshot of the NLP software Grammarly correcting my grammar as I wrote this article.

Screenshot of the dialogue translation mode on the Samsung Galaxy S7, which interprets a spoken conversation between two people.
Machine translation is one of the best-known applications of NLP. Traditional machine translation was done by rule-based techniques, where NLP researchers attempted to manually encode the entire grammar of both the source and target language into their computer programs, as if they were writing a grammar book. The rule-based techniques failed spectacularly.
There is a well-known but probably apocryphal story about the Cold War-era machine translation system which translated “the spirit was willing, but the flesh was weak” to Russian and back into English, rendering it as “the vodka was good but the meat was rotten”.
Of course, nowadays nearly everybody has a much more powerful translation tool in their pocket… although this is really an illusion, as the translation itself on your mobile phone probably takes place on Google’s servers rather than on the device itself.
Virtual assistants, or chatbots, such as Alexa and Siri belong to a subset of NLP called natural language dialogue systems. They allow a user to control a mobile device, car, sound system, smart fridge, or similar by voice commands, and are capable of holding a rudimentary dialogue with a human within the narrow domains for which they have been designed.
We’ve all tried to test the limits of a chatbot at some point. Fortunately, humans are just as predictable as robots. When I worked on the development of corporate virtual assistants for some years, we found that the commonest things that people asked the bots were ‘what are you wearing?’, ‘do you have a boyfriend?’, and so on. It was quite easy to program the bots to have a witty answer to these inputs.
Google and Bing run NLP algorithms on both your search queries and the documents that they have crawled, in order to match the two together and identify the best documents to return for a given user’s query.
In any domain where large amounts of text are commonplace, NLP is likely to be able to deliver value. A few of the most common applications are:
It is a common use case to classify incoming documents into different groups. A standard NLP problem is that of document classification systems, and over the years many algorithms have been developed to address this problem. Classic examples include:
It is often useful to know if a sentence has positive or negative emotions. Many companies are using this technology to monitor social media and quickly react to negative mentions of their product. For example, if a mobile phone is prone to overheating, or an electric car tends to over-accelerate, consumers may vent on Twitter before trying to contact the company through its official channels.
Sentiment analysis is a field of NLP where texts are analysed automatically for emotional content, and sometimes the sentiments are broken down to the level of all the entities (companies, locations, persons) mentioned in a text. Sentiment analysis is non-trivial to solve because of the use of sarcasm, complex sentence constructions, and tone, which are hard for computers to process.
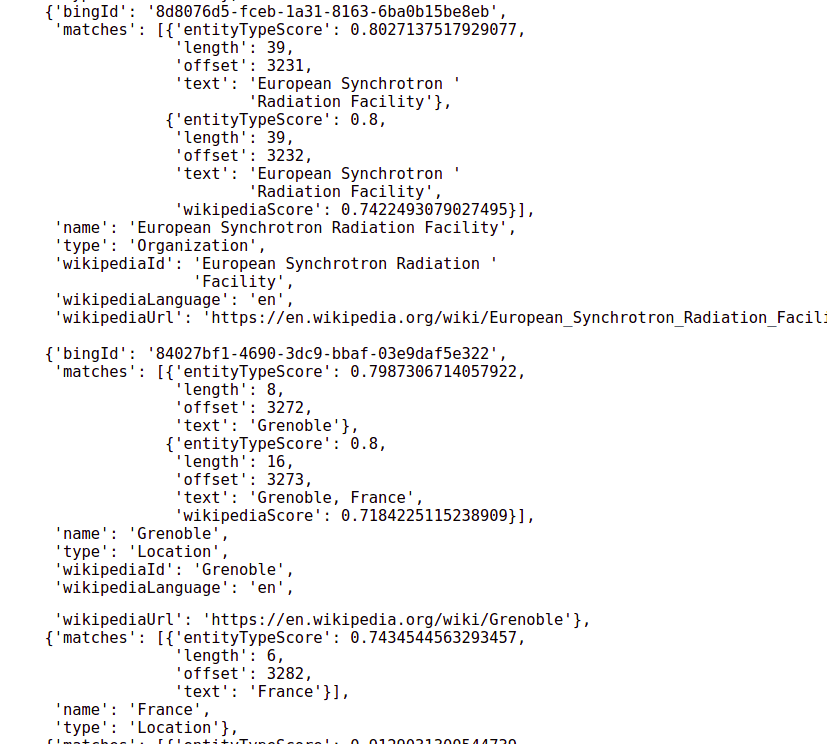
Output of a named entity recognition algorithm. This takes an English sentence and identifies all words mentioned which refer to entities, providing Wikipedia links where applicable and assigning a confidence score to each one.
It is often desirable to identify and disambiguate what’s known as ’named entities’ in a document. A few examples:
A jobseeker’s anonymised CV. Recruiters commonly use anonymisation tools in order to share candidates’ details with employers without running the risk that the employer will bypass the recruitment agency.
The advent of big data has brought with it a growing awareness of the importance of data protection, giving rise to regulations such as the GDPR in Europe. This has also opened up new opportunities in NLP, as many organisations are now required to anonymise all documents before sharing with third parties. NLP can be used to scrub out, or replace with dummies, all personal names, phone numbers, addresses, or similar in a document. The techniques behind this are similar to those of named entity recognition but the goal is the opposite: to obfuscate rather than extract data.

An anonymised technical due diligence report by Fast Data Science. Natural language processing is useful for scrubbing sensitive company data.
Traditionally, NLP evolved from the field of linguistics, where computer scientists attempted to program computers with ever more elaborate representations of human language. Over time, NLP has evolved from rule-based approaches to machine learning-based approaches, and is now grouped under AI, or artificial intelligence.
AI is a very broad term encompassing a variety of domains, from image processing and face recognition to audio transcription, customer churn prediction, and fraud detection. In its broadest definition, AI covers all techniques in use to make computers mimic human thought, which would include the whole of NLP.
NLP techniques can be divided into three groups:
Rule-based systems are the easiest to explain. For example, a human would write a computer program to follow instructions such as “if the word begins with a capital letter, and it’s not at the beginning of a sentence, and the following word also begins with a capital, and the following word is a verb, then it is a personal name”. Rule-based NLP systems, although easily understandable and highly transparent, are hard to maintain and scale, and do not perform very well. The only area that I have seen rule-based systems in use in industry is chatbots, but even chatbots are moving away from rule-based approaches and heading towards machine learning techniques.
Traditional machine learning-based systems are more powerful than rule based systems, and require that the NLP data scientist chooses a model and provides a set of training and validation data. Examples of this approach include the Naive Bayes algorithm for spam detection. You can build a passable spam detector with just 100 examples of spam emails and 100 of ham emails, and the simple rules of the Naive Bayes algorithm.
The state of the art for all NLP applications is now deep learning based systems. Deep learning based systems rely on neural networks. They require a way to convert a text document into numbers, which can be fed into a neural network which can then learn to perform the task at hand.
Deep learning NLP methods typically require very large amounts of training data, and they result in large model sizes and need more computing power to train and run. Often, an NLP data scientist will require millions of documents before training a deep learning-based system becomes practical. Deep learning is not an option for many NLP projects, because the amount of training data available is too small.
The main advantage of deep learning-based systems is that data scientists do not need to spend a long time designing and tweaking machine learning algorithms. They can typically take an existing neural network design out of the box. If they are very lucky then they can take a pre-trained network such as BERT, which has already been trained on texts in the language in question, and they can perform just a minimal amount of re-training to adapt the model for their use case. This technique is called transfer learning.
The second main advantage of deep learning-based systems is that they can deliver astonishing levels of accuracy, because they are able to adapt to the extremely complex structure of human language.
For example, LSTM and Transformer based neural networks have been able to resolve pronouns over several sentences. Neural network models have been also able to translate sentences such as “I saw the moon. It was beautiful” into Spanish or German correctly, where the translation of “it” depends on the gender of “moon” (so Spanish renders the last sentence as “she was beautiful” and German renders it as “he was beautiful”).
In text classification, the Transformer-based models are currently state-of-the-art, however this field is advancing rapidly and every year a new neural network design is published which beats the previous cutting-edge model.
I hope this article helped you understand better the main points of NLP.
If your organisation has a large set of text documents and you would like assistance in extracting value from them, please contact us.
Unleash the potential of your NLP projects with the right talent. Post your job with us and attract candidates who are as passionate about natural language processing.
Hire NLP Experts
This is an article based on my presentation on “The Role of Artificial Intelligence in Expert Investigations and the Preparation of reports” which I gave at the Expert Witness Conference on 20 May 2026.

Many companies and organisations have large datasets that are stored in a very unstructured format. For example, you could work for a US based healthcare provider or insurer and have patient records stored in a free text format such as HL7 files or PDFs. A building regulator, land registry, or mortgage provider may have texts and accompanying diagrams from thousands of building inspections or land title deeds. A patent attorney’s office may have records of patent applications in PDF format.

On 20 May, I attended the Expert Witness Conference in Dublin, Ireland, organised by La Touche Training. It was an eye opening event with a mixture of lawyers and expert witnesses in different fields from Ireland and abroad. The event was chaired by Mr Justice Michael Peart, with a keynote address by the Honourable Mr Justice David Barniville, President of the High Court of Ireland.
What we can do for you