Unleash the potential of your NLP projects with the right talent. Post your job with us and attract candidates who are as passionate about natural language processing.
Hire NLP ExpertsTechnologies like Machine learning (ML), artificial intelligence (AI) and natural language processing (NLP) have revolutionised the way businesses gather data, interpret it, and use the insights to improve processes, ROI, customer satisfaction, and other aspects of their business.
It’s now become more important than ever to properly structure your efforts as far as ML and AI are concerned, and for that you must understand how the machine learning workflow/artificial intelligence workflow generally works.
Machine learning workflows describe the phases which are implemented during a typical ML project. These phases usually include data collection and data pre-processing, building of datasets, model training and improvements, evaluation, and then finally, deployment and production.
While we can agree that the above steps – which we will discuss in great depth – may be accepted as a standard, there’s always room for improvement. Because when you first come up with a machine learning workflow, you need to define the project before anything else, and then utilise an approach which best works regarding the business application you are targeting.
So, right from the outset, we need to learn to not forcefully fit the model into a rigid workflow. It’s always good to build a flexible workflow which lets you start small with ease and then scale-up to a production-level solution.
Let’s quickly go over the steps involved in machine learning workflows – which may vary on a project-to-project basis, although the five steps we’ve highlighted below are typically included:
Gathering data for your machine learning workflow is one of the most crucial stages. During the data collection phase, you define the potential accuracy and usefulness of your project or use case through the quality of the data you acquire.
To collect data in an optimal way, you must identify your sources and then aggregate the data into a single dataset.
Moving forward after the data collection, you must pre-process it. This ensures that the data is cleaned, verified, and formatted into a usable dataset. This may be a relatively straightforward process if the data is being collected from a single source.
But when you aggregate the data from several sources (which is usually the case), you need to ensure that all the data formats match, that every data source is equally reliable, and that there are no potential duplicates.
We must now break down our processed data into three main datasets:
Training set: We will use this to train the ML algorithm initially, teaching it how information must be processed. The set will define model classifications by setting parameters.
Validation set: We shall use this to estimate how accurate the model is, using the dataset to fine-tune all our model parameters.
Test set: As the name implies, we will use this to determine how accurate the models are and how well they perform. This is a great way to uncover any potential issues or ‘bad’ trainings in the model.
After we have our datasets, we can train our model. This is where we will feed our training set to our algorithm, so that it can learn the right parameters and features needed for classification.
Once the training is complete, we can refine our model using the validation dataset. This may entail modifying certain variables or discarding them altogether. It also includes the process of tweaking model-specific settings (called hyperparameters), until we arrive upon an acceptable accuracy level.
Once we have determined an acceptable set of hyperparameters and optimised our model accuracy, we can proceed to test our model. Testing will, naturally, use the test dataset which will help you verify whether your models are using accurate features. Once you receive the feedback, you can then decide whether it’s best to train the model for better accuracy, tweak output settings, or deploy it without further ado.
Now that we’re familiar with the above steps, let’s explore them in more detail to better understand the processes involved at each stage and the outcomes to expect.
Let’s start with the basics:
The ML model is simply a piece of code, meaning that a data scientist or engineer can make it “smart” by training it with the right data. So, whatever you feed the model, that’s what it will output. You can literally train it to give correct or false predictions – in case of the latter, feed it garbage, and garbage it shall return!
Gathering data pretty much depends on the kind of project we are working on. For example, if we’re working on an ML project where real-time data must be utilised, then we can build ourselves a nice IoT (Internet of Things) system which uses different sensory data. We can collect this data set from multiple sources such as a database, file, sensor and other sources as well. However, we won’t be able to use the collected data in a direct way to perform the analysis part – this is because there may be missing data, ‘noisy’ data, unorganised/unstructured text or very large values.
This is why we need to put our data through ‘pre-processing’. With that said, there are free datasets available on the internet – e.g. Kaggle is commonly used to make ML models, which happens to be the most visited site for those looking to practice ML algorithms.
This is one of the most important steps in machine learning when it comes to training models, as it will help you to build a model that’s accurate. Furthermore, we have an 80/20 rule in machine learning which means: data scientists must set aside 80% of their time for data pre-processing and 20% to perform the actual analysis.
Data pre-processing or data preparation is a process used to clean raw or unstructured data – so, the data is collected from real-world sources and then converted to a ‘clean’ dataset. To put it another way, whenever you collect data from a variety of sources, it comes to you in a completely raw format which is, as you might imagine, not ready for analysis. Therefore, specific steps are needed to convert that data into a small and clean dataset, and hence, we call it data pre-processing.
Equally important to understand is why we need data pre-processing every time we want to train ML models. We do this simply to achieve desirable or feasible results from the applied model in our ML and DL (deep learning), and AI projects.
Real-world data, when it is collected, is usually messy. It will almost always come to you in the form of:
Noisy data – Also called outliners, noisy data can be the result of human errors (it is people, after all, who collect the data) or, perhaps, a technical issue with the device at the time it was used to collect the data.
Missing data – You can have missing data on your hands when it is not created continuously or there are technical issues with the application (such as with an IoT system).
Inconsistent data – This is usually the result of human errors (e.g. mistakes made with names or values) or even duplication of data.
The data collected is usually of three types:
Numeric data (age, income, etc.)
Categorical data (nationality, gender, etc.)
Ordinal data (values, e.g. low, medium, or high)
No matter how stringent a standard we follow for data collection, you must understand that it will contain errors, inconsistencies, and shortcomings. Data pre-processing is a critical step, therefore, and should not be bypassed under any circumstances, no matter how good you believe the quality of your initially collected data is!
You may be wondering how data pre-processing is done. It’s fairly straightforward as long as you follow these pre-processing techniques:
Data conversion – Since ML models can only understand numeric features, we need to convert the categorical and ordinal data into numeric features.
Overlooking missing values – Each time we come across any missing data in the dataset, we should remove the specific row/column of data, as per our need. This is a very efficient method although it should not be performed if you have a lot of missing values in your dataset – don’t overlook them!
Filling up the missing values – As we come across missing data in our dataset, we must fill up the missing data manually. The mean, median, or highest frequency value should be typically used.
Machine learning – As we come across missing data, we should be able to predict what data needs to be present at the empty position. We can use our existing data to determine this.
Outliers detection – There’s a small chance that some error data may be present in the dataset which deviates significantly from other observations in it. For example, the weight of a person being entered as “800 kg” due to a typo where an extra zero was typed.
We shall now use our pre-processed data to train the best performing machine learning model possible. At this stage of your machine learning workflow or artificial intelligence workflow you need to understand two concepts:
Supervised learning – In a supervised learning environment, the AI system is presented with labelled data, so that means each piece of data is tagged with the appropriate label. Supervised learning itself is divided into two sub-categories:
Classification – The target variable is categorical in nature; i.e. the output may be classified into classes, either Class A, B, or whatever you want it to be. So, in a classification problem, the output variable is always a category (‘red’ or ‘blue’, ‘spam’ or ‘no spam’, ‘disease’ or ‘no disease’, and so on).
Some of the most commonly used classification algorithms include Naive Bayes, Logistic Regression, Support Vector Machine and Random Forest.
Regression – The other sub-category is regression. This is where the target variable is continuous in nature; i.e. it has a numeric output.
Imagine you’re looking at a graph where the X-axis indicates “test scores” and the Y-axis indicates “IQ”. So, we will try to create the ‘best fit line’, using it to predict any average IQ value which isn’t present in the given data.
Some of the most commonly used regression algorithms include Support Vector Regression, Random Forest, Ensemble Methods, and Linear Regression.
Unsupervised learning – In an unsupervised learning environment, the AI system is presented with unlabelled and uncategorised data, where the system’s algorithms act upon the data without any prior training. Naturally, the output will depend on the algorithm coding. So, subjecting your system to unsupervised learning is yet another way of testing your AI.
As with supervised learning, unsupervised learning may also be divided further into a sub-category:
Clustering – This is where we divide a set of inputs into groups. Unlike classification, the groups are not known in advance, so the task itself is unsupervised, as you might imagine.
Common methods for using clustering include: Boosting, Hierarchical Clustering, Spectral Clustering, K-Means Clustering, and more.
Just to give you a quick overview of the models and their categories:
Machine learning branches out into supervised learning and unsupervised learning; supervised learning has two sub-categories (classification and regression), while unsupervised learning has one subcategory (clustering).
To properly train our ML model, we must initially split it into three sections:
Data training
Data validation
Data testing
We will train our classifier using the training dataset, tune our parameters through the validation dataset, and then test our classifier’s performance on the unseen test dataset.
One thing to keep in mind is that while you train the classifier, only the training and validation set are available – we will deliberately set aside the test dataset while training the classifier. The test set, therefore, becomes available to use once we start testing our classifier.
It’s important to understand how these three sets work:
Training – The training dataset is the actual material through which the system or computer learns processing of information. The training part will be performed through ML algorithms. A specific set of data will be used for learning, which must also fit the classifier’s parameters.
Validation – The validation dataset refers to the cross-validation which is mainly used in applied machine learning to estimate the skill level of a ML model on unseen data. A set of unseen data will be used from the training data to help tune the classifier’s parameters.
Test – The test dataset is a set of unseen data which is used merely to assess a fully-assessed classifier’s performance.
Once our data is divided into these three segments (training, validation, test), we can begin the training process.
In your dataset, the training set is used to build up the ML model, while the validation set is used to validate the ML model you build. Data points in this training set are not included in the validation set. You’ll find that in most cases, a data set is divided into a training set and validation set (or a test set as some people prefer to use that instead) in each iteration of the model – or into a training set, validation set and test set for each iteration.
The ML model may use any of the methods we described in step #3. Once the model has been trained, we may use the same trained model in order to predict the unseen data. After this, we can come up with a confusion matrix which would tell us how well we trained our model.
A confusion matrix features four parameters:
True positives
True negatives
False positives
False negatives
Here’s a quick description of each:
True positives – Cases where we predicted true and the predicted output is correct.
True negatives – Cases where we predicted false and the predicted output is correct.
False positives – Cases where we predicted true but the predicted output is false.
False negatives – Cases where we predicted false but the predicted output is true.
Our goal should be to get the most number of values as true positives and true negatives in order to get the most accurate model possible. As for the size of your confusion matrix, that will depend on the total number of classes there are.
The accuracy of your model through the confusion matrix can also be determined by this formula:
True positives + true negatives divided by total number of classes = accuracy (percentage)
Model evaluation is a crucial part of the machine learning workflow process as it helps you in finding the best model which represents your data, and how well your chosen model will perform in the future.
To improve our model, we should tune the hyperparameters and improve its accuracy. Additionally, we should use the confusion matrix to increase the total true positives and true negatives.
When training your ML model and improving your machine learning workflow or artificial intelligence workflow, you should also be familiar with how the NLP (natural language processing) pipeline works.
A natural language processing pipeline involves a series of steps which help in transforming raw data into a chosen output – e.g. a response, summary, or label.
Each step in the NLP pipeline performs a highly specific function, such as lemmatisation, named entity recognition, semantic analysis, or tokenisation.
The natural language processing workflow outlines the set of rules and processes to be used for executing, managing, and monitoring the pipeline in regards to any of the above functions.
Therefore, if you’re working with ML model training, artificial intelligence workflows, and machine learning workflows, then you should be familiar with what natural language processing pipelines and workflows are. Follow a clear as well as consistent workflow and pipeline, and you can bet that your data will be fully standardised, clean, and ready for analysis.
As expert NLP consultants, we can guide you on everything related to natural language processing pipelines and workflows, no matter what the intended use or application.
As you become better at defining your machine learning workflow and artificial intelligence workflow, there are many best practices you can follow to ensure that you achieve the desired outcome:
Defining project goals are important as it ensures your ML models add value to a process and not redundancy. Try to understand the roles you want your model to fulfil, the restrictions that may exist in terms of implementation and the criteria it must meet or exceed.
Evaluate the processes your data relies on, how it is collected and the volume of the data. This will help you determine the specific data types and data points you require to form predictions.
Research and experiment!
The entire premise of implementing artificial intelligence workflows, machine learning workflows, and understanding natural language processing pipelines – is to improve the accuracy and efficiency of your current model training process.
So, before you implement an approach, perhaps, study how other teams implemented similar projects. In any case, experiment with the existing or new approach, and then extensively train and test your model.
As you develop your approach, your end result is going to be a ‘proof of concept’, more or less. But this proof must be translated into a functional product, which can be achieved through creating a machine learning API, A/B testing, and user-friendly documentation containing the code, methods, and the ways of using the model.
Need more guidance on any of the steps we’ve discussed on machine learning workflows? Our data analysts are always available to offer insights and advice according to your business goals.
Tags
machine learning workflow
artificial intelligence workflow
natural language processing pipeline
We discuss all the steps involved in an efficient machine learning workflow along with understanding the importance of your natural language processing pipeline.
Looking for experts in Natural Language Processing? Post your job openings with us and find your ideal candidate today!
Post a Job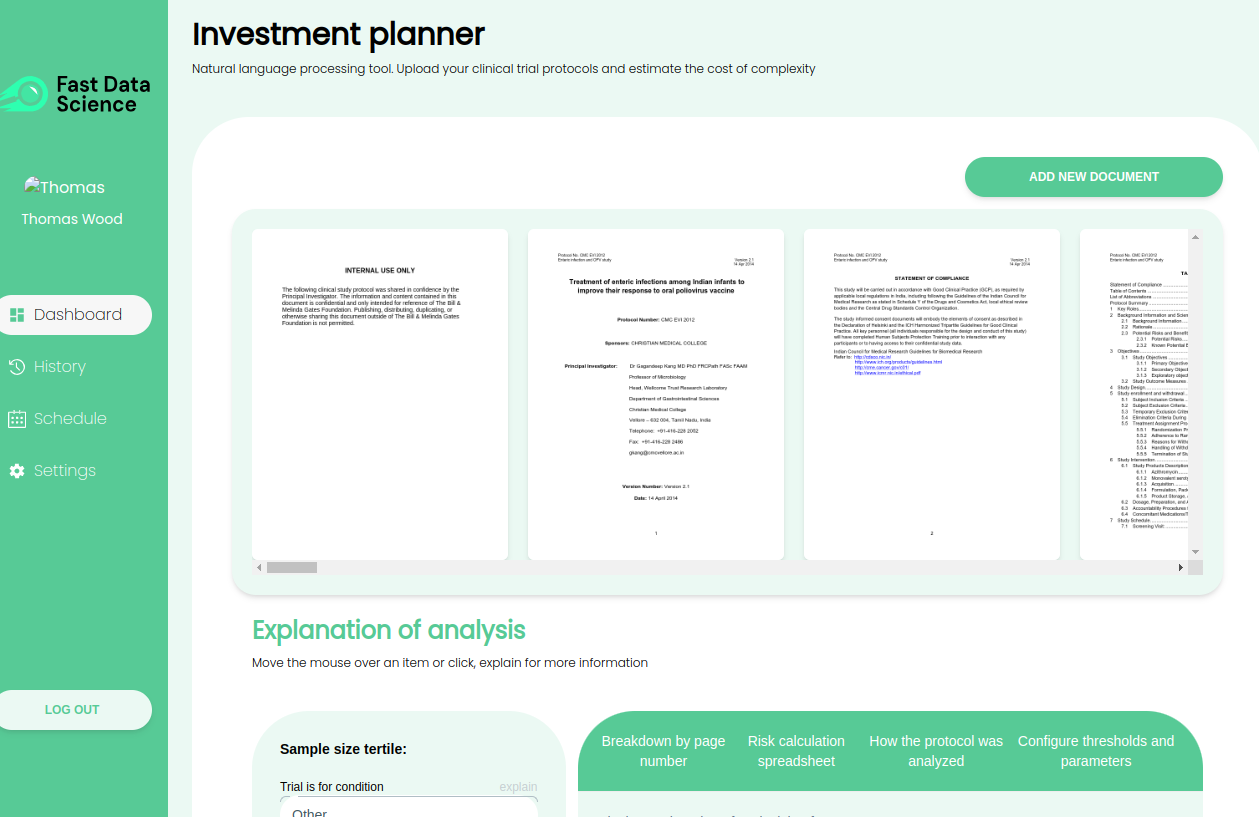
Modelling risk and cost in clinical trials with NLP Fast Data Science’s Clinical Trial Risk Tool Clinical trials are a vital part of bringing new drugs to market, but planning and running them can be a complex and expensive process.
What we can do for you